本文實例講述了MongoDB Shell 命令。分享給大家供大家參考,具體如下:
原始文件請到我的github上去下載:https://github.com/yangqingxian/mongodb
這里先講幾件事:
1、這是第三次修改這篇文章了,也是第一次正真意義上的使用 github 來控制版本,想想還是有點小激動的:)
2、其中的內容結構與 mongodb基礎命令是一致的,只不過添加了很多內容進去,適用于想進一步學習mongodb數據庫的人
3、我其實也是菜鳥,所以我會用很白目的語言來解釋其中的內容,如果你也跟我一樣,那就兩只鳥一起飛吧
4、接下來的內容均是我對《MongoDB大數據權威指南(第2版)》的摘記
5、其中的命令例子并沒有事先創建好數據庫、集合,都是要用到的時候臨時寫的,注意理解
mongodb數據庫結構與傳統關系型數據庫的比較,便于理解接下來的內容
數據庫->集合->文檔
數據庫->表 ->列
--------------------數據庫內容------------------
查看所有數據庫
show dbs
刪除數據庫
db.dropDatebase()
--------------------集合內容--------------------
創建集合
db.createCollection()
查看所有集合/表
show collectionsshow tables
選定某一集合
use db_name
查看集合的信息
db.stats()
刪除一個集合,但是需要先指定一個數據庫,即先執行 use db_name
db.dropDatabase()
修改集合的名稱
db.collection_name.renameCollection('new_name')----------------------文檔內容---------------------
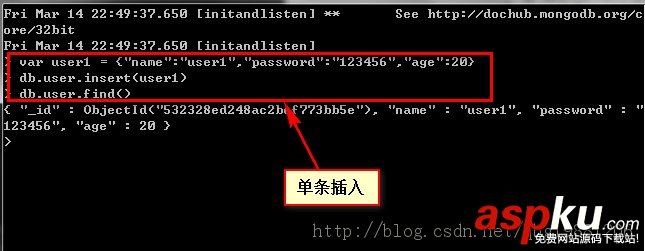
插入數據
db.collection_name.insert(document)db.collection_name.save(document)
查詢數據多條數據
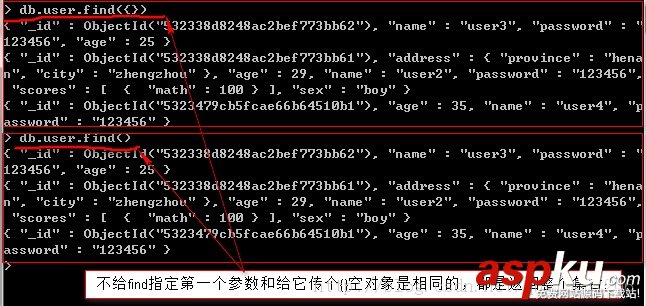
db.collection_name.find()
1、可以指定返回的內容
參數解釋
db.collection_name.find({query_term:value},return_key_name:1}) a find()函數的第一個參數是查詢條件,即匹配該內容的文檔都會被篩選出來,如果沒有查詢條件,則輸入{},不可以為空
b find()函數的第二個參數是指定返回的內容,例如一個student的集合中的一個xiaoming文檔中包含多條內容,姓名、學生號、家庭住址等,現在我只想看姓名,不想查詢的時候返回xiaoming文檔的全部內容,就可以使用這種'鍵名:1'的形式,后面的1表示篩選出該內容并正序輸出,0表示篩選出除了該內容的其余部分,-1表示逆序跟1一樣的結果
c 可以返回多條記錄,這里只是舉個例子,還是拿ixaoming的例子
{'name':1,'student_id':1}這樣就返回了兩個信息,一個name,一個student_id
2、查詢嵌套信息
結合二維數組理解下面的這個信息
{'name':'yang','sex':'man','skill':[{'php':1},{'mongodb':4},{'redis':5}],'favorite_food':'meat'}其中如果使用skill來作為find()的查詢條件的話,千萬別寫成這樣
---錯誤例子---
db.self.find({'skill':[{'php':1}]})這樣是查不到的,因為這樣mongodb會將{'skill':[{'php':1}]}解析成skill數組下只包含'php':1這一條記錄的內容,上面的例子明顯不符合這一要求,所以查詢不到
---正確的例子---
db.self.find({'skill.php':1})這里使用了 . 告訴mongodb數據庫去匹配skill數組下php為1的內容,重點在于skill下是否有'php':1這一條記錄
---正確例子2---
如果一定要使用上面的錯誤例子的方式查詢數據,可以使用$elemMatch參數,注意該參數使用的位置
db.self.find({'skill':{$elemMatch:{'php':1}}})這里的$elemMatch是作為條件操作符來使用的
查詢單條數據
db.collection_name.findOne()
skip 跳過查詢的最開始的數量,limit,限制返回數量,sort,當 x:1 表示正序,x:-1 表示逆序
db.collection_name.find().skip(Number).limit(Number).sort({x:1})計算符合查詢條件的文檔的數量
db.collection_name.find().count()
count()函數默認情況下會忽略skip()或limit()函數,例如假設student集合中有4個文檔,下面的三條語句將顯示不同的結果
db.student.find().limit(1).count() 結果為4,count忽略了limit(1)的條件
db.student.find().limit(1).count(true) 結果為1,為count()傳入參數true
獲取結果的唯一值
db.collection_name.distinct('key_name')也是查詢的函數,只不過他比起find()會將查詢結果顯示唯一值,而不是根據原有集合中,文檔的數量來顯示結果,結合關系型數據庫中的distinct來理解,舉個例子,有一個圖書集合--books,該集合下有書名,作者,出版日期等信息,注意,一個作者可能寫了很多本書,現在我想查看在該集合中有多少作者,如果我直接使用上面的find()函數來搜索的話
db.books.find({},{'writer':1}) 這樣會將全部的作者列出來,但是很多都是重復的,因為find()是根據文檔數量來返回結果的,而distinct()會將結果篩選,
其中重復的部分
db.books.distinct('writer')將查詢結果分組
db.collection_name.group()
data1={ "_id" : ObjectId("552a330e05c27486b9b9b650"), "_class" : "com.mongo.model.Orders", "onumber" : "002", "date" : ISODate("2014-01-03T16:03:00Z"), "cname" : "zcy", "item" : { "quantity" : 1, "price" : 4.0, "pnumber" : "p002" } }data2={ "_id" : ObjectId("552a331d05c275d8590a550d"), "_class" : "com.mongo.model.Orders", "onumber" : "003", "date" : ISODate("2014-01-04T16:03:00Z"), "cname" : "zcy", "item" : { "quantity" : 10, "price" : 2.0, "pnumber" : "p001" } } data3={ "_id" : ObjectId("552a333105c2f28194045a72"), "_class" : "com.mongo.model.Orders", "onumber" : "003", "date" : ISODate("2014-01-04T16:03:00Z"), "cname" : "zcy", "item" : { "quantity" : 30, "price" : 4.0, "pnumber" : "p002" } } data4={ "_id" : ObjectId("552a333f05c2b62c01cff50e"), "_class" : "com.mongo.model.Orders", "onumber" : "004", "date" : ISODate("2014-01-05T16:03:00Z"), "cname" : "zcy", "item" : { "quantity" : 5, "price" : 4.0, "pnumber" : "p002" } } db.orders.insert(data1)db.orders.insert(data2)db.orders.insert(data3)db.orders.insert(data4) 接下來展示group()函數
例1
db.orders.group({key:{data:1,'item.pnumber':1},initial:{'total':0},reduce:function (doc,out){out.total+=doc.item.quantity}}) 首先是按照data和ietm數組中的pnumber分組
接著定義了輸出變量total,記錄每個產品的總數
接著是定義處理函數,也就是reduce中的函數,注意,傳入參數的先后順序,第一個參數表示當前進行分組的文檔,第二個參數表示initial,所以doc能直接調用doc.item.quantity,即文檔的內容,out能調用out.total,即initial的內容
例2
db.orders.group({keyf:function(doc){return {'month':doc.date.getMonth()+1};},initial:{'total':0,'money':0},reduce:function (doc,out){out.total+=doc.item.quantity*doc.item.price},finalize:function (out){out.avg=out.money/out.total;return out;}}) 首先,這個例子展示了keyf的用法,他返回了一個新的字段--month,接下來mongodb會按照month的計算結果分類
接著,就是在keyf以及finalize的函數中都有傳入參數,其實這個參數跟reduce中的參數名字沒有關系,這里寫在一起主要是為了便于理解其含義
最后就是在finalize中臨時創建了一個變量avg,這個avg在最后也是會被輸出的
最后一點,在函數中處理結果都是會被return的
----------------使用條件操作符來篩選查詢結果------------------
一般情況下都使用在find()的第一個參數內部,作為篩選條件使用
---$gt,$lt,$get,$lte,$ne---
db.collection_name.find({key_name:{$gt:value}})注意操作符的位置,看例子可以便于理解
db.student.find({'height':{$gt:180}})表示篩選出學生集合中身高高于180的學生
可以同時使用兩個操作符來指定范圍
db.student.find({'height':{$gt:180,$lt:220}})這兩個的使用方法跟上面是一樣的,但是需要單獨拎出來講,因為有點特殊
---$in,$nin---
db.student.find({'height':{$in:[170,180,190,200]}})表示篩選出身高為170,180,190,200的學生,$nin就是篩選除了170,180,190,200之外的學生
---$all---
上面的$in中的內容是‘或'的形式,只要你的身高是170,或180,或190,或200,那么你就符合篩選條件,而$all則是且的關系
db.student.find({'height':{$all:[170,180,190,200]}})這句話的意思是你的身高既是170,又是180,又是190,又是200才能滿足條件
---$or---
db.student.find({$or:[{'score':100},{'sex':man}]})上面的例子中,score:100與sex:man是‘或'的關系,結合下面的例子就可以看出$or的作用了
db.student.find({'score':100,'sex':'man'})其中的score:100與sex:man是且的關系
limit(x)函數加skip(y)函數=$slice:[y,x]
具體使用方法可以看下面這個例子
db.student.find({},{'height':{$slice:[10,5]}})還是那句老話,注意$slice的位置,這句話表示篩選身高第11到15的人,第一個參數是skip()的參數,第二個是limit()
limit()函數是限制返回文檔的數量的,$size是篩選符合數量的數組的,看下面的例子就明白了
先在數據庫中添加以下信息
message={'cds':[{'first_song':'hello'},{'second_song':'world'},{'third_song':'again'}]}db.songs.insert(message)接著我們來查詢一下上述結果
db.songs.find({'cds':{$size:2}})無返回結果,因為cds數組里有3組數據
db.songs.find({'cds':{$size:3}})返回全部結果,注意一點,這里是作為find()函數的第一個參數傳入的,所以是篩選條件
篩選含有特定字段的值
db.collection_name.find({key_name:{$exit:true}})返回存在該字段的文檔,注意,這里是存在該字段,而沒有指定該字段的具體內容
根據數據類型篩選返回結果
db.collection_name.find({'key_name':{$type:x}})其中的x取值內容有很多,這里就不介紹了,因為太多了看一遍也沒用
在篩選中使用正則表達式
db.collection_name.find({'key_name':/ /})在/ /中添加正則表達式的內容
更新數據
db.collection_name.update({original_key:original_value},{new_key:new_value})1、只要原 collection 中包含 original_key:original_value 就會被選中成為操作對象
2、整個 collection 都會被更新成 new_key:new_value ,而不單單就只是更新 original_key:original_value
相較于上面會更新整個集合,下面添加了 $set: 的形式來只進行部分字段的更新
db.collection_name.update({original_key:original_value},{$set:{new_key:new_value}})上面使用$set更新了一條字段,可以使用$unset刪除一條字段
db.collection_name.update{{},{$unset:{key:value}}}如果此更新數據不存在就創建這一條數據,加第三個參數為 true 就可以實現了
db.collection_name.update({original_key:original_value},{new_key:new_value},true)或者下面的形式也可以
db.collection_name.update({original_key:original_value},{new_key:new_value},{upsert:true})update 只會更新第一條滿足條件的記錄,但是想更新多條記錄時,將第三個參數設置為 false,第四個參數設置為 true,而且還要設置 $set
db.collection_name.update({original_key:original_value},{$set{new_key:new_value}},false,true)------------------插入數據——數組部分--------------------
插入數據
db.collection_name.update({original_key:value},{$push:{new_key:new:value}}) 注意,如果original_key不存在,則會被創建,并且定義為數組的形式,new_key:value則是第一個值
如果original_key存在,并且數數組,則插入new_key:value,如果不是數組,則報錯
一次性插入多個值,前面是使用$push一次插入一個值,如果想插入多個值的話,需要使用下面的內容
db.collection_name.update({original_key:value},{$push:{new_key:{$each:['value1','value2','value3']}}})注意這里的$push是針對數組操作的,也就是$each后面的內容都將添加到new_key的數組中
與$push對應,$pop刪除數組中的數據
db.collection_name.update({original_key:value},{$pop:{{original_key:1}}})注意,這里的1表示刪除的數量,可以是2,3等整數,表示從數組的后端開始刪除,也可以是-1等負數,表示從數組的前端開始刪除
前面的$pop可以指定刪除的數量,但是不能指定刪除的條件,$pull則可以
db.collection_name.update({original_key:value},{$pull:{key1:value1}})$pull會刪除掉key1中所有value1的數據,注意,是刪除key1中的value1數據,不是刪除key1,所以只要key1數組中包含了value1就會被刪除掉value1
與$pull類似,$pullAll可以刪除掉多個數據
db.collection_name.update({original_key:value},{$pullAll:{key1:['value1','value2','value3']}})$addToSet是一個非常實用的向數組添加數據的命令,如果該數據不存在則添加,存在就不會重復添加了
db.collection_name.update({original_key:value},{$addToSet:{new_key:{$each:['value1','value2','value3']}}})設想一下,如果這里不添加$each的情況,如果不添加$each,則會變成往數組new_key中直接添加新的數組
['value1','value2','value3']
可以嘗試一下,理解$each的功能,回到$addToSet上來,如果原數組中就存在value1,value2,value3則不會添加,如果不存在,則將沒有的添加進去,有的也不會重復添加,彼此之間不是互相影響的。
原子操作
這里就不解釋什么叫原子操作了,對于我們使用者來說只要知道怎么采用原子操作就可以了
db.collection_name.findAndModify({query:{key:value},sort:{key2:1/-1},update/remove:true,new:true}) query 指定查詢的文檔
sort 排序,1,-1的含義這里就不解釋了,跟上面一樣
update/remove 表示操作
new 表示返回最終的修改結果,可以不填
刪除所有查找到的數據
db.coolection_name.remove({key:value})刪除一張表
db.collection_name.drop()
查看集合的索引
db.collection_name.getIndexes()
創建索引
db.collection_name.ensureIndex({key:value}) 前面是根據key:value的形式創建索引的,接下來就為一集合的某一字段全部創建索引
db.collection_name.ensureIndex({key:1})復合索引的創建就是在其中多添加幾個內容
刪除索引
db.collection_name.dropIndex({key:value})刪除所有索引
db.collection_name.dropIndexes()
前面我們操作的都是一個集合,接下來我們要學習簡單的操作多個集合了,有兩種方式,手動或者使用DBRef
先創建兩個集合
collection1={'name':'yang','sex':'man'}collection2={'id':1,'name':'yang','math':60,'pe':30,'chinese':60}db.student.save(collection2)db.yang.save(collection)接下來就是大致思路了
yang=db.yang.findOne()db.student.find({'name':yang.name})mongodb不支持像傳統的關系型數據庫那樣的多表操作,mongodb都是需要先將數據保存好,再來調用的,如上面的yang保存的就是find()查詢所需要的內容,需要先將數據從數據庫中讀出保存好再來調用,其中yang.name就等于'yang'
接下來就是使用DBRef引用數據庫了,調用DBRef需要傳入三個參數,第一個調用的collection_name,id,db_name,這個可選,還是上面的這個例子,接下來使用DBRef的方式,這玩意我搞不定
希望本文所述對大家MongoDB數據庫程序設計有所幫助。
新聞熱點






疑難解答