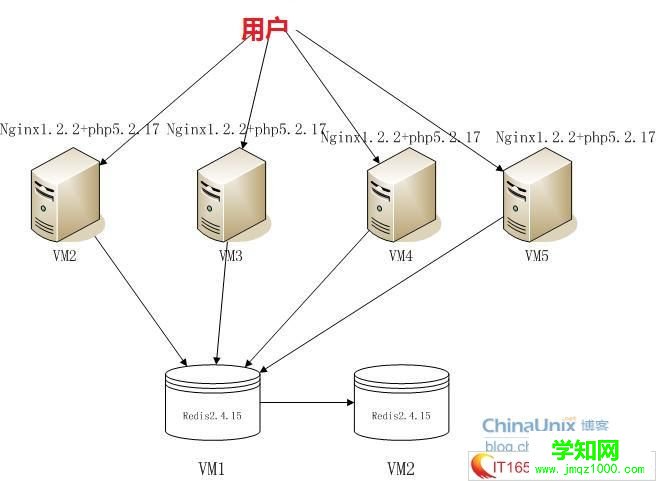
緩存穿透:
認識
緩存穿透是指查詢一個一定不存在的數據,由于緩存是不命中時需要從數據庫查詢,查不到數據則不寫入緩存,這將導致這個不存在的數據每次請求都要到數據庫去查詢,造成緩存穿透。
解決辦法:
對所有可能查詢的參數以hash形式存儲,在控制層先進行校驗,不符合則丟棄。還有最常見的則是采用布隆過濾器,將所有可能存在的數據哈希到一個足夠大的bitmap中,一個一定不存在的數據會被這個bitmap攔截掉,從而避免了對底層存儲系統的查詢壓力。
也可以采用一個更為簡單粗暴的方法,如果一個查詢返回的數據為空(不管是數 據不存在,還是html' target='_blank'>系統故障),我們仍然把這個空結果進行緩存,但它的過期時間會很短,最長不超過五分鐘。
緩存雪崩
認識
如果緩存集中在一段時間內失效,發生大量的緩存穿透,所有的查詢都落在數據庫上,造成了緩存雪崩。
這個沒有完美解決辦法,但可以分析用戶行為,盡量讓失效時間點均勻分布。大多數系統設計者考慮用加鎖或者隊列的方式保證緩存的單線程(進程)寫,從而避免失效時大量的并發請求落到底層存儲系統上。
解決方法
在緩存失效后,通過加鎖或者隊列來控制讀數據庫寫緩存的線程數量。比如對某個key只允許一個線程查詢數據和寫緩存,其他線程等待。
可以通過緩存reload機制,預先去更新緩存,再即將發生大并發訪問前手動觸發加載緩存
不同的key,設置不同的過期時間,讓緩存失效的時間點盡量均勻
做二級緩存,或者雙緩存策略。A1為原始緩存,A2為拷貝緩存,A1失效時,可以訪問A2,A1緩存失效時間設置為短期,A2設置為長期。
相關教程:redis視頻教程
以上就是淺談redis的緩存穿透和緩存失效的預防和解決的詳細內容,更多請關注 其它相關文章!
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。
新聞熱點





疑難解答