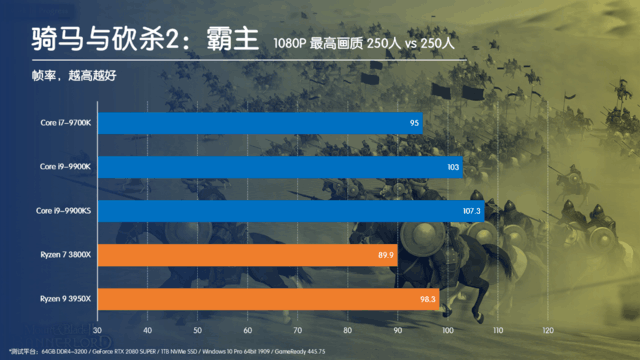
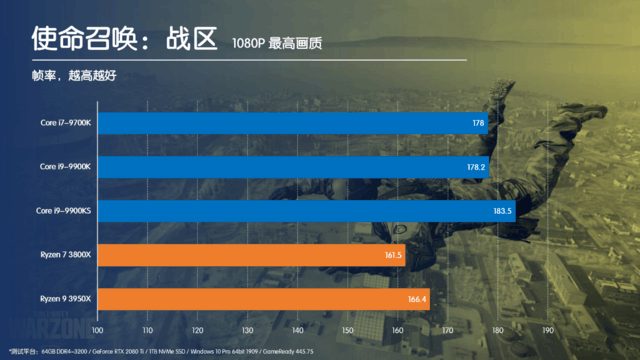
大家都知道,最近一段時間游戲大作頻發,先是《使命召喚:戰區》火爆全球,緊隨其后的《騎馬與砍殺2》也在一片叫好聲中登頂Steam單周銷量榜首。熱門游戲自然少不了大量的測試,細心的玩家就會發現,在這些測試中,英特爾的CPU性能表現都要遠優于AMD的Ryzen系列,特別是同樣核心規模的時候,這種優勢就愈發的明顯。
為什么英特爾的處理器要比AMD的更適合玩游戲呢?除去在主頻上的優勢之外,很重要的一點就是英特爾在CPU本身的架構上,要比AMD的Zen/ Zen2架構,更適合應對游戲這種包含大量復雜邏輯的運算形式,這其中涉及到的很重要的一個部分,就是CPU內部的“片內總線”。
片內總線負責連接CPU芯片內部的各個模塊,包括CPU核心以及顯示核心、內存控制器等輔助模塊。作為各模塊數據交換的途徑,片內總線的效率,會對CPU性能有著顯著的影響,甚至可以說片內總線的結構,決定著一顆CPU最合適的應用場景。片內總線的結構通常包括星形、線形、樹形、環狀(Ring)、網狀(Mesh)以及全連接這幾種。其中星形就是早期單核心CPU的主要結構,Core作為中央節點,其他模塊都和它鏈接。進入多核時代后,星形結構就不再適用了。線形和樹形同樣不適合,因此目前能見到的片內總線方案,主要就是Ring、Mesh和全連接這三種方式。
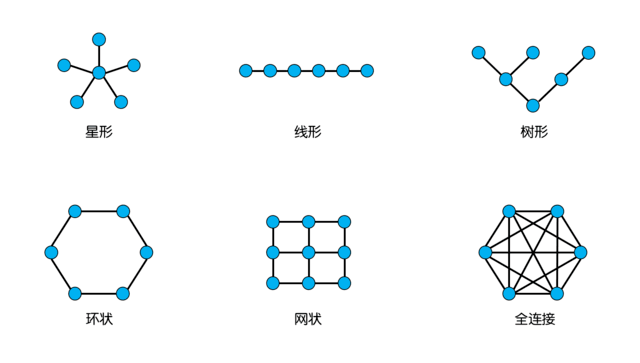
全連接的方式,從結構上來說很理想,因為CPU內部每一個核心節點都能直連另外任意節點,信息傳遞效率最高,延遲也最低。但是全連接的復雜度會隨著核心數量的增加而大幅提升的,比如4核心需要6條內部通路,而8核心就需要28條,16核心就需要120條。如此復雜的線路在設計和制造都是災難性的,因此目前只有AMD在Zen架構上,采用了縮水版的全連接方式。
所謂縮水,就是Zen/Zen2架構,實際上只做了4核心的全連接,這樣只需要6條互聯通路,在復雜度上還算可以承受。那么Ryzen和ThreadRipper那么多核心數量是怎么來的呢?那就要說到“膠水”(Multi-Chip-Module)技術了。

在Zen架構中,AMD把這4個全連接的核心成為一個CCX(CPUComplex)模塊,2個這樣的CCX通過IF互聯總線連接,組成了一個芯片(一級膠水)。在Zen2架構中,AMD將這樣一個芯片稱作CCD(CoreChiplet Die),然后再通過組合多個CCD與I/O模塊(cIOD),組成一顆完整的Ryzen3000系列CPU(二級膠水)。
經過兩次膠水之后,全連接方式的優勢就被完全抵消了,因為在跨CCX進行數據交換要通過IF總線,跨CCD溝通甚至要通過銅電路,由此帶來的延遲將變得非常夸張。同時,也正是因此,Ryzen系列處理器非常依賴Windows操作系統的調用機制,AMD也多次與微軟合作希望通過打補丁的方式讓Windows10系統在進行線程跳轉時,盡可能地在CCX內部完成,以此來降低延遲帶來的性能損失,然而收效甚微。

既然膠水結構有這么大的劣勢,為什么AMD還堅持使用這樣的結構呢?原因很簡單——省錢。通過使用這種模塊化的結構,縮小了單一芯片的規模,AMD能夠更好的控制芯片制造的良品率,畢竟用兩個8核心CCD“粘”成一個3950X的難度遠小于造一個完整的16核心的芯片,而且萬一CCD里面壞了兩個核心還能封包成3600X繼續賣。同時,在頻率和計算效率受限的情況下,AMD也是不得不靠膠水技術來堆核心數量,以換取市場上的一席之地。
自己有工廠生產CPU芯片的英特爾,在片內總線的選擇上,更偏向對效率的追求。所以針對不同的應用場景使用了不同的結構。比如在MSDT平臺上,因為核心數量相對少,大多數家用級用戶很少需要去應對大規模并發數據運算的情況,因此選擇了延遲控制更好的環形總線(RingBus)。
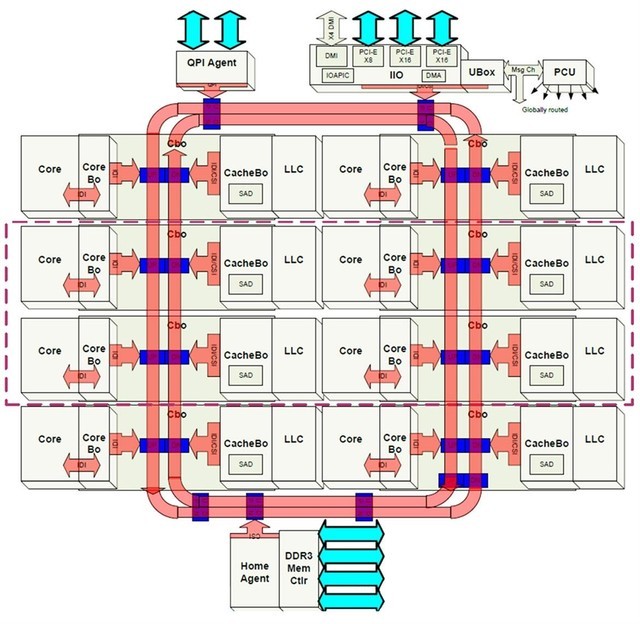
所謂RingBus就是通過一個環路(實際上包括順時針和逆時針兩個同心環)將所有的核心以及其他模塊串在一起,核心(或模塊)與總線連接的地方被稱為RingStop。如此一來,核心之間的數據交互結構距離都不會超過RingStop的一半(因為Ring是雙向的),保證了數據交換的延遲盡可能低且穩定。同時,再增加核心的時候,也不會增加互聯的復雜度,只需要增加一個新的RingStop即可。
當然RingBus也不是萬能的,當核心數量超過12個的時候,會因為RingBus過長而導致平均延遲增大到不可接受的地步。為此英特爾在需要更多核心的HEDT平臺上,引入了網狀(Mesh)結構。相比于Ring結構,Mesh解決了規模擴增的靈活性,因為在Mesh結構中加入新的節點,并不會導致延遲像Ring結構那樣線性的增加。實際上Mesh針對早期HEDT平臺所使用的2-Ring結構,還降低了內部核心數據交換延遲以及RAM和I/O的訪問延遲。不過HEDT平臺并不是我們這篇文章的重點,所以這里就不展開了。
讓我們打個比方來解釋一下這上面說到的這3種片內互聯結構的差異:英特爾的Ring總線就相當于在一個大會議室里進行圓桌會議,每一個人就相當于一個核心節點。數據在核心之間的傳遞過程就相當于進行一次“擊鼓傳花”的游戲,只要人數(節點)不太多,那么在任意兩個人之間傳遞東西,所花的時間都會控制在一個非常少的水平。
Mesh架構則很像我們上學時候的教室,里面的每一個學生就相當于一個核心節點。這時候如果要把一個東西在任意兩個點之間傳遞,只需要選擇最合適的路徑傳遞過去就可以了,所需要的時間依然會很少。
相比之下,AMDRyzen處理器的CCX相當于4個人坐在一個房間里,一個CCD就是一棟樓里面有這樣兩個房間,Ryzen93950X或更高的TR系列則由2棟或更多棟樓組成。因此當數據在CCX里的4個人之間傳遞的時候,效率還算不錯,但如果要傳遞給隔壁房間里的人,就要開門出屋,也就是延遲會大幅度增加。如果還要傳遞給其他樓里的人,那就要出房間,下樓上樓再進房間,過程中浪費的時間就可想而知了。
實際的測試結果很好的體現出了片內總線的結構差異帶來的性能區別:
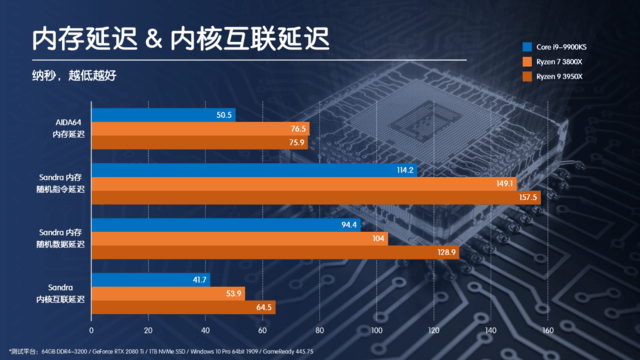
采用Ring結構的Corei9-9900K在延遲方面大幅優于同樣8C/16T的Ryzen7 3800X,而對于采用雙CCD進行片上膠水的Ryzen93950X更是遙遙領先。而在游戲過程中,CPU本身就需要頻繁的對內存進行讀寫操作,這就將Ring結構的優勢充分發揮了出來。即使對于騎砍2這樣的大規模集團作戰的游戲來說,理論上應該能夠很好的發揮多核心的優勢,但是因為Zen2架構的內核互聯延遲太高,因此在我們開篇的測試數據中,16C32T的3950X反而被Corei9-9900K遠遠甩開。
考慮到無論是英特爾還是AMD,目前的微架構都將至少還要延續2代產品,因此可以肯定地說,在未來一段時間內,如果要為打游戲而裝電腦,英特爾處理器還是最靠譜的選擇。
新聞熱點





疑難解答