AMD正式發布了這款采用革命性HBM顯存的全球首款公版水冷顯卡,這款卡實在是太過驚艷,驚艷了業界也驚艷了我。過了一年,AMD發布了采用14nm的Polaris顯卡,在業界掀起了紅色革命,AMD的獨顯市場份額也從2成上升到了3成。又過了一年,AMD終于在今年7月發布了久違的旗艦級顯卡——RADEON RX VEGA 64/56,眾多A飯翹首期盼的AMD卡皇終于降世了!

此時此刻,距離AMD上一代基于Fiji(斐濟)核心的旗艦顯卡Radeon R9 Fury X誕生已經過去了兩年零一個多月的時間,這在以往是非常不可思議的。
尤其是過去一年多來,NVIDIA Pascal家族逐次推進,從高到低完整覆蓋,AMD方面雖然也有全新的Polaris(北極星)核心,但畢竟是個小核心,在中低端市場上表現穩健,卻沒有一位老大哥帶頭,總是缺乏底氣。
Vega核心最早的說法是2016年10月份就會登場,但在眾多玩家尤其是A飯們的焦急等待中,又是十個月過去了,Vega才終于瓜熟蒂落,而此時距離其主要競爭對手GTX 1080/1070的誕生,也已經有一年零三個月之久了。
對于Vega為何遲到這么久,AMD高級副總裁兼Radeon技術事業部首席架構師Raja Koduri對我們解釋說:
一是14nm工藝,這是AMD第一次同時在CPU和GPU上使用同一種工藝。
二是Vega架構是全新設計的,從底層開始都煥然一新,而如今設計一種全新的高性能計算架構,不但要做好高端游戲,還要滿足圖形工作站、高性能計算、機器學習等各方面的需求。
當然,AMD作為唯一一家同時擁有高性能CPU、GPU計算平臺的企業,本身并不是多么財大氣粗,同時面臨Intel、NVIDIA兩大可以分別專注一個領域的強敵,可以說相當不易,走過的每一步都值得尊重。

回來再說Vega,作為一個全新設計的高性能核心,它肩上的擔子是相當重的,玩游戲也只是一個方面,它要做的事兒多著呢。
事實上在此之前,Vega家族已經逐漸開始生根發芽,甚至可以說逐漸枝繁葉茂了。
在服務器和高性能計算領域,我們見到了Radeon Instinct MI25,直面NVIDIA Tesla系列,完美搭檔自家EPYC服務器處理器;
在圖形工作站領域,我們有了Radeon Pro WX 9100、Radeon Pro SSG,不但競爭NVIDIA Quadro系列,后者還首創了顯卡集成SSD,容量高達2TB,后續據稱還有Radeon Pro 64/56;
在游戲開發領域,Radeon Vega Frontier Edition風冷版、水冷版大家也都不陌生了,這也是AMD對于NVIDIA Titan X/Xp的一個回應;
在游戲領域,AMD也是卯足了勁,首發就有三款產品(也可以說四款),而且后續還有更多驚喜!

【Vega架構解析:AMD GPU五年來最革命性進步】
不知不覺,Radeon這個顯卡品牌已經誕生17年了,也伴隨太多DIYer走過了青春歲月,而時代在變化,Radeon面臨的需求也越發多樣化。
AMD在技術白皮書中特別指出,除了傳統游戲不斷沖擊視覺技術極限,GPU還面臨著更廣泛需求的挑戰,從機器學習到專業視覺化,從虛擬化到虛擬現實,GPU的計算能力也在快速跟上,以滿足超大數據集的需求,但是GPU存儲能力并未得到顯著提升。
為此,AMD全新設計了Vega架構,這也是GCN圖形架構誕生五年以來,AMD GPU最革命性的變化。

不過,新核心的變化實在太多了,涉及幾乎所有方面,而且很多都過于專業,所以這里我們之挑選其中幾個要點和大家分享。
1、Vega 10:高集成度的大核心
Vega架構的第一個產品是“Vega 10”,一個相對大規模的芯片,面向高分辨率游戲、VR虛擬現實、高性能計算和機器學習、高負載工作站等領域。
它采用14nm LPP FinFET工藝制造,集成了125億個晶體管,核心面積486平方毫米。
相比之下,28nm工藝的上代大核心Fiji集成了89億個晶體管,面積卻有596平方毫米,也就是說Vega 10核心晶體管規模多了整整40%,面積卻縮小了18%!
另外,同樣14nm工藝的Polaris 10核心集成57億個晶體管,核心面積232平方毫米,Vega 10與之相比晶體管多了1.2倍,面積增大了1.1倍,集成度也有所提高。
Vega 10核心經過優化后,可以充分利用FinFET工藝的低漏電率優勢,頻率也高于以往任何Radeon顯卡,官方標稱最高加速頻率就有1.67GHz,而實際運行中完全可以超過1.7GHz,實測中甚至見到過1.75GHz。
相比之下,上代Fiji核心最多只能加速到1GHz左右,Polaris 10最高則是超過1.3GHz。
Raja表示,14nm工藝對CPU和GPU來說都很平衡,在CPU上可以實現高頻率,GPU上則可以實現高集成度,比如Vega就因此比Fiji核心要小得多,但是性能高出很多。
Vega 10核心依然有64個計算單元、4096個流處理器,規模上和Fiji是一樣的,但憑借高進的架構和更高的頻率,單精度浮點計算性能達到了驚人的13.7TFlops(每秒13.7萬億次計算),而且還支持16位數學計算,半精度浮點性能達27.4TFlops。
Vega 10還是AMD第一個使用了Infinity Fabric互連設計的GPU核心,也就是Zen處理器里的那一套。這種低延遲的SoC型互連總線可以在芯片的不同模塊之間提供一致性通信,也使得芯片設計更加彈性靈活,可以做到模塊化,能隨時根據需要加入不同配置和模塊。
Vega 10芯片中,Infinity Fabric連接著圖形核心與其他主要邏輯模塊,包括顯存控制器、PCI-E控制器、顯示引擎、視頻加速器等等,也為未來的APU奠定了基礎。

2、全新顯存架構和高帶寬緩存控制器(HBCC)
GPU通常需要在本地顯存中保存所需要數據集或者資源的全部,因為走PCI-E等外部通道的話,將無法保證足夠的帶寬或延遲。
隨著軟件內存管理的日益復雜,這對開發者提出了越來越高的挑戰,而顯存成本又決定了不可能把容量做到特別大。
為此,Vega架構可以將本地顯存作為末級緩存使用。如果GPU要訪問的部分數據不在顯存之內,可以通過PCI-E總線獲取所需內存頁面,并保存在高帶寬緩存中,而不是讓GPU停下來,等待完成全部所需資源的復制。
頁面通常比整個紋理等資源小得多,復制可以迅速完成,后續訪問就直接從緩存中拉取,延遲自然非常低。

這主要得益于Vega架構新增的高帶寬緩存控制器(HBCC),可以將遠程內存作為本地緩存使用,同時可以將本地顯存作為末級緩存使用。
HBCC支持49位尋址,最多能訪問512TB虛擬尋址空間,而現代CPU的尋址空間也不過48位,同時比最多10+GB的顯存也多了幾個數量級。

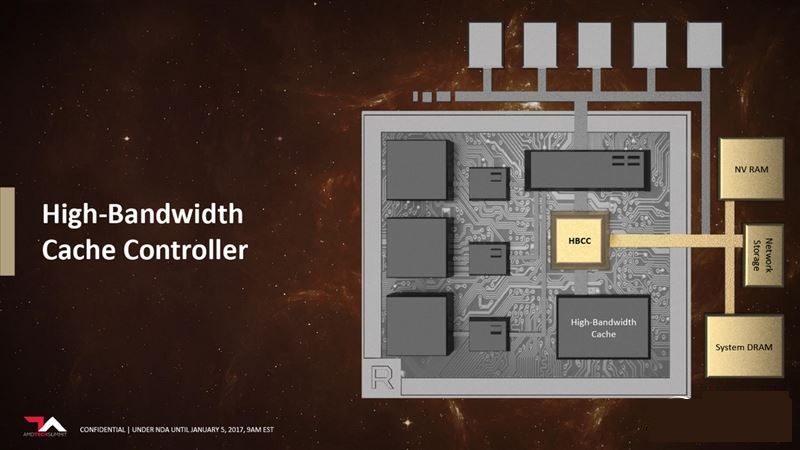
HBCC被視為Vega架構中最大的革新,簡單地說可以把整個系統內存當做顯存來使用,相當于一塊顯卡可以擁有TB級別的高速顯存,無論性能還是容量都不是事兒。
換言之,它實現了某種程度上的一體化內存池,這部分AMD稱之為“HBCC內存區”(HMS)。
Radeon Pro SSG之所以能板載2TB SSD,就是得益于這種設計,消除了從GPU到SSD之間的隔閡,可以直接訪問其中的數據,從而大大降低延遲和過載。
為了將這種設計發揮到極致,Vega架構其他部分也做了針對性調整,比如說二級緩存就扮演著中心角色,容量翻番到4MB,所有圖形區塊都直接與其相連,而以往像素引擎是有自己的緩存的。
當然,HBCC設計也需要開發者去學習適應,才能挖掘和釋放其最大潛力,而且它也不是必須使用的,開發者如果對顯存容量和性能沒有特別高的要求,仍然可以走傳統路線。

顯存方面,Vega搭配了第二代高帶寬顯存HBM2,類似Fiji那樣與GPU核心整合封裝,使用硅中介層與GPU物理互連。
得益于新的技術和工藝,HBM2最多可以堆疊8個,單顆容量最大8GB,Vega專業卡就用了兩顆供16GB,RX Vega家族則配備了兩顆供8GB。
同時,HBM2每個堆棧的位寬達1024-bit,因此只需很低的頻率,就能提供極高的帶寬。
在顯卡驅動控制面板中,用戶可以根據自己的需要,手動調整HMS的容量范圍。

3、下一代計算單元(NCU)
AMD GCN架構的核心模塊是計算單元(CU),Vega也是如此,但同樣做了全面翻新,官方稱之為下一代計算單元(NCU)。

NCU的一個亮點變化就是加入了快速堆疊運算(Rapid Packed Math/RPM),允許兩個FP16半精度的運算同時執行,并支持豐富的16位浮點和整數指令集,包括FMA、MUL、ADD、MIN/MAX/MED、Bit Shift等等。
一般來說,日常游戲、3D渲染對單精度FP32、雙精度FP64要求比較高,而在大規模深度計算中,FP16半精度十分關鍵。
Vega首次支持半精度計算,每個NCU擁有64個ALU,可以靈活地執行緊縮數學操作指令,比如每個周期可執行512個8位數學計算,或者256個16位計算,或者128個32位計算。這不僅充分利用了硬件資源,也能大幅度提升Vega在深度學習上的性能。

RPM專門用于加速FP16半精度的運算速度,比如新的著色器可以利用RPM,在AMD一直引以為傲的TressFX毛發渲染中,將每秒能渲染的頭發數量增加一倍,因此,RPM可以幫助GPU核心進行更快更強的的物理計算。
NCU還可以同時進行計算和圖形處理,并且能夠根據負載不同而變換SIMD單元寬度,結果就是以往需要多個計算單元才能完成的任務,現在只需一個就能搞定,不會造成浪費。
種種改進結合,Vega 10核心可以每秒鐘執行27萬億次浮點計算,或者55萬億次整數操作。

4、下一代幾何引擎
Vega的整個幾何引擎針對更高三角形吞吐量做了優化,增加了新的快速硬件路徑,比以往更有彈性、可編程性。
Vega幾何引擎里的創新很多,最具代表性的當屬新的原語著色器(Primitive Shader),可以合并部分幾何處理流水線,拋棄隱藏的、沒必要的原語,代之以新的高效著色類型,而且啟動非常快,每時鐘周期的峰值原語剔除率是以前的四倍。

Vega 10擁有四個幾何引擎,加入了新的原語著色器之后,每時鐘周期的最大原語吞吐量可以超過17個,而以前只能做到4個。
同時,Vega架構還加入了新的智能負載分配器(IWD),可以根據實際情況持續調整流水線設定,更好地平衡各個幾何引擎之間的負載,提高利用率。

5、下一代像素引擎
隨著4K/5K/8K超高分辨率和240Hz高刷新率顯示器的出現和普及,以及VR虛擬現實的進一步發展,顯卡像素吞吐能力也面臨著越來越大的壓力,Vega為此重新設計了像素引擎,加入了大量新功能。
新聞熱點






疑難解答
圖片精選