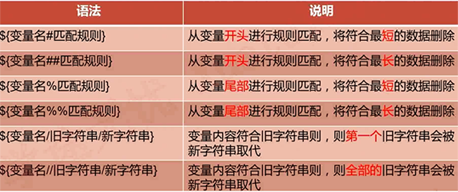
案例:從頭開始匹配,將符合最短的數(shù)據刪除 (#)
variable_1="I love you, Do you love me"echo $variable_1variable_2=${variable_1#*ov}echo $variable_2
案例:從頭開始匹配,將復合最短的數(shù)據刪除(##)
varible_3=${variable_1##*ov}echo $varible_3
案例:替換字符串,只替換第一次匹配成功的(/)
echo $PATHvar6=${PATH/bin/BIN}echo $var6
案例:替換字符串,符合條件的全部替換 (//)
var7=${PATH//bin/BIN}echo $var7

簡單舉例(用的比較少)
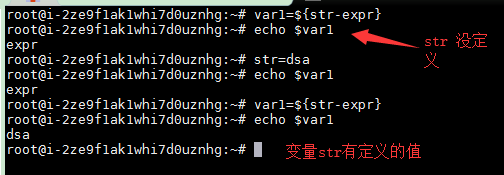
var=${str-expr}如果變量 str 沒有定義,那么var=expr
如果變量 str的字符串中有值,那么 變量 var 的值就等于 str變量的值
計算字符串的長度

案例1
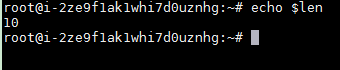
var="hello world"len=${#var}echo $len
案例2
var1="zhang biao"len=`expr length "$var1"`echo $len
獲取字串在字符串中的索引位置 (把字串拆分成一個個的字串,最先匹配到的第一個就會返回)

案例
var="quickstart is a app"ind=`expr index "$var" start`echo $ind

案例 查找一個不存在的字串,返回 1
ind=`expr index "$var" uniq`echo $ind

計算字串的長度 (只能從頭開始匹配,用的不多)

例子:找不到返回 0,不是從頭開始匹配
var="quickstart is a app"sub_len=`expr match "$var1" app`echo $sub_len

從頭開始匹配
sub_len=`expr match "$var" quick*`echo $sub_len

sub_len=`expr match "$var" quick.*`echo $sub_len

抽取字串

案例:方法一
提取var1中索引從10開始一直到結尾的字符串,索引下標從0開始
var1="kafka hadoop yarn mapreduce"sub_str1=${var1:10}echo $sub_str1
案例:方法二
從第10個位置開始提取5個字符串
sub_str2=${var1:10:5}echo $sub_str2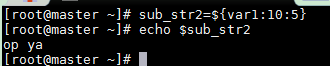
案例:方法三
取最后的5位
sub_str3=${var1: -5}echo $sub_str3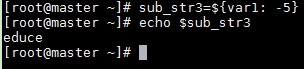
案例:方法四
取從最后開始取最后5位,注意 var1: -5 之間有空格
sub_str3=${var1:(-5)}echo $sub_str3
案例:方法五
提取最后5位的前兩位
sub_str3=${var1: -5:2}echo $sub_str3
注意: 使用expr,索引計數(shù)是從1開始計算 使用${string:position},索引計數(shù)是從0開始
需求描述:
變量 string="Bigdata process framework is Hadoop,Hadoop is an open source project"
執(zhí)行腳本后,打印輸出string字符串變量,并給出用戶以下選項:
(1)、打印string長度
(2)、刪除字符串中所有的Hadoop
(3)、替換第一個Hadoop為Mapreduce
(4)、替換全部Hadoop為Mapreduce用戶輸入數(shù)字1|2|3|4,可以執(zhí)行對應項中的功能;輸入q|Q則退出交互模式
思路分析:
1、將不同的功能模塊劃分,并編寫函數(shù)、
2、實現(xiàn)第一步所定義的功能函數(shù)
#!/bin/bash# string="Bigdata process framework is Hadoop,Hadoop is an open source project" function print_tips{ echo "********************************************" echo "(1)打印string長度" echo "(2)刪除字符串中所有的Hadoop" echo "(3)替換第一個Hadoop為Mapreduce" echo "(4)替換全部Hadoop為Mapreduce" echo "********************************************"} function len_of_string{ echo "${#string}"} function del_hadoop{ # 把hadoop替換為空 echo "${string//Hadoop/}" } function rep_hadoop_mapreduce_first{ echo "${string/Hadoop/Mapreduce}"} function rep_hadoop_mapreduce_all{ echo "${string//Hadoop/Mapreduce}"}3、程序主流程的設計
example.sh
#!/bin/bash# string="Bigdata process framework is Hadoop,Hadoop is an open source project" function print_tips{ echo "********************************************" echo "(1) 打印string長度" echo "(2) 刪除字符串中所有的Hadoop" echo "(3) 替換第一個Hadoop為Mapreduce" echo "(4) 替換全部Hadoop為Mapreduce" echo "********************************************"} function len_of_string{ echo "${#string}"} function del_hadoop{ # 把hadoop替換為空 echo "${string//Hadoop/}" } function rep_hadoop_mapreduce_first{ echo "${string/Hadoop/Mapreduce}"} function rep_hadoop_mapreduce_all{ echo "${string//Hadoop/Mapreduce}"} while truedo echo " 【string=$string】" echo print_tips read -p "Pls input your choice(1|2|3|4|q|Q):" choice case $choice in 1) len_of_string ;; 2) del_hadoop ;; 3) rep_hadoop_mapreduce_first ;; 4) rep_hadoop_mapreduce_all ;; q|Q) exit ;; *) echo "Error,input only in {1|2|3|4|q|Q}" ;; esacdone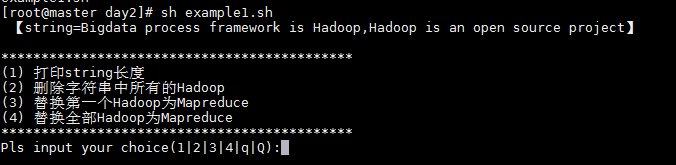
語法格式

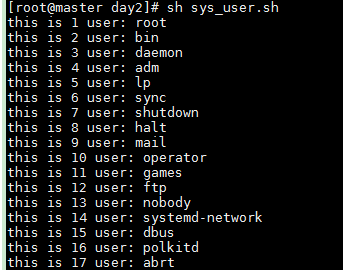
例子1: 獲取系統(tǒng)的所有用戶并輸
cat /etc/passwd | cut -d ":" -f 1
使用 cut 對 : 進行切割,獲取第一個及時用戶的名字
for循環(huán)能以空格、換行、tab鍵作為分隔符
sys_user.sh
#!/bin/bash# index=1for user in `cat /etc/passwd | cut -d ":" -f 1`do echo "this is $index user: $user" index=$(($index + 1))done
例子2: 根據系統(tǒng)時間計算今年或明年
echo "this is $(date +%Y) year"echo "this is $(( $(date +%Y) + 1)) year"

總結: ``和$()兩者是等價的,但推薦初學者使用$(),易于掌握;缺點是極少數(shù)UNIX可能不支持,但``兩者都支持 $(())主要用來進行整數(shù)運算,包括加減乘除,引用變量前面可以加$,也可以不加$
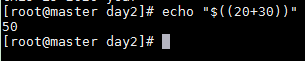
echo "$((20+30))"
示例3
echo $((100+30))echo $(( (100 + 30) / 13 ))echo $(( $num1 + $num2 * 2))
shell 語法不是很嚴格,是否加$都會計算
num1=50num2=70echo "$((num1 + num2))"
例子4:
今天是今年的第多少天
echo $(date +%j)

根據系統(tǒng)時間獲取今年還剩下多少星期,已經過了多少星期
echo "this year have passed $(date +%j) days"echo "this year have passed $(($(date +%j) / 7)) weeks"

今年還剩余多少天
echo "there is $((365 - $(date +%j))) days before new year"echo "there is $(((365 - $(date +%j)) / 7 )) weeks before new year"

示例5:判斷nginx進程是否存在,如果沒有需求拉起這個進程
example_3.sh
#!/bin/bash## grep -v 過濾掉 grep 進程nginx_process_num=$(ps -ef|grep nginx|grep -v grep|wc -l) if [ $nginx_process_num -eq 0 ];thensystemctl start nginxfi

shell編程系列4--有類型變量:字符串、只讀類型、整數(shù)、數(shù)組
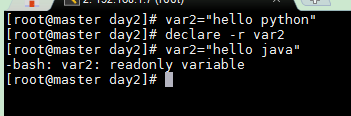
declare -r 將變量設置為只讀類型
var2="hello python"declare -r var2var2="hello java"
declare -i 將變量設為整數(shù)
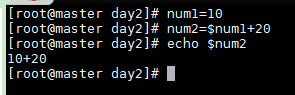
默認把變量當做字符處理
num1=10num2=$num1+20echo $num2
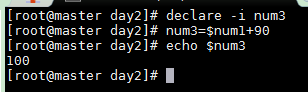
聲明為整數(shù)
declare -i num3num3=$num1+90echo $num3
declare -a 將變量定義為數(shù)組
定義數(shù)組
declare -a arrayarray=("jones" "make" "kobe" "jordan")列出數(shù)組所有元素
echo ${array[@]}
列出其中指定的一個
echo ${array[1]}
計算數(shù)組長度
echo ${#array[@]}
輸出數(shù)組中元素長度
echo ${#array[0]}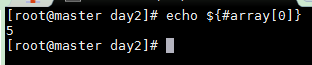
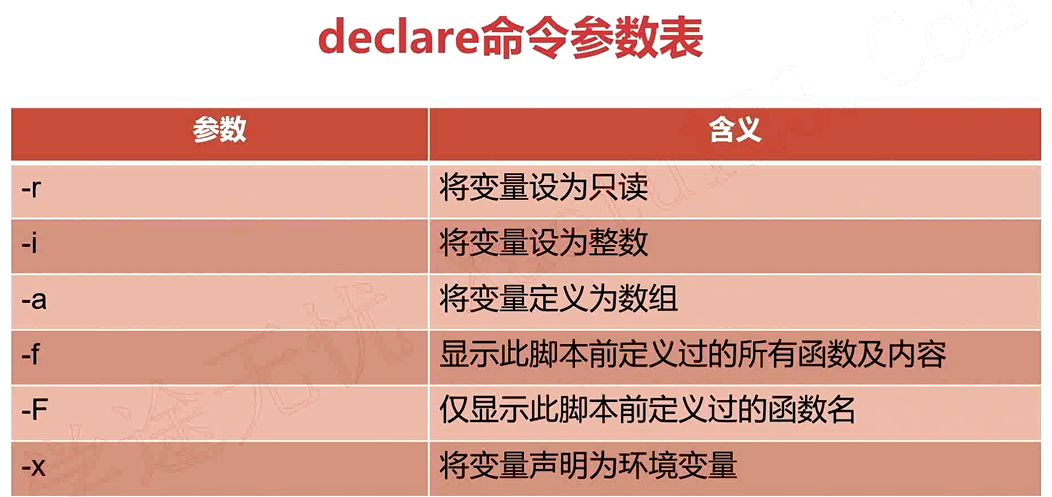
-f 顯示此腳本前定義過的所有函數(shù)和內容 ,-F 進顯示腳本前定義過的函數(shù)名
declare -fdeclare -F
數(shù)組常用的方法(僅供參考,實際生產用的少)
array=("jones" "mike" "kobe" "jordan")輸出數(shù)組內容: echo ${array[@]} 輸出全部內容 echo ${array[1]} 輸出下標索引為1的內容 獲取數(shù)組長度: echo ${#array} 數(shù)組內元素個數(shù) echo ${#array[2]} 數(shù)組內下標索引為2的元素長度 給數(shù)組某個下標賦值: array[0]="lily" 給數(shù)組下標索引為1的元素賦值為lily array[20]="hanmeimei" 在數(shù)組尾部添加一個新元素 刪除元素: unset array[2] 清空元素 unset array 清空整個數(shù)組 分片訪問: ${array[@]:1:4} 顯示數(shù)組下標索引從1開始到3的3個元素 內容替換: ${array[@]/an/AN} 將數(shù)組中所有元素包含an的子串替換為AN 數(shù)組遍歷: for v in ${array[@]} do echo $v donedeclare -x 將變量聲明為環(huán)境變量
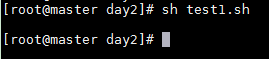
test1.sh
#!/bin/bash# echo $num5
運行 shtest1.sh
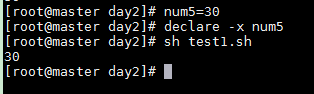
當使用declare -x 變量后,就可以直接在腳本中引用了
num5=30declare -x num5
到此這篇關于詳解shell 變量的高級用法示例的文章就介紹到這了,更多相關shell 變量用法內容請搜索武林網以前的文章或繼續(xù)瀏覽下面的相關文章希望大家以后多多支持武林網!
新聞熱點






疑難解答
圖片精選