隨著Windows10操作系統的發布,DX12這一全新的API也進入了我們的眼球。與以往的任何一代DX API都不同,從DX12開始,應用、游戲的開發者們可以接觸到CPU或GPU的底層,并進行有效率的優化調用,充分地發揮硬件的效率。
生意似乎不太好的AMD,與微軟進行了一次深層次的合作,針對DX12的環境下,對自家的CPU和GPU作出了三大優化,這是否能成為AMD在DX12時代力挽狂瀾的籌碼呢?
一、增強多核心CPU工作效率
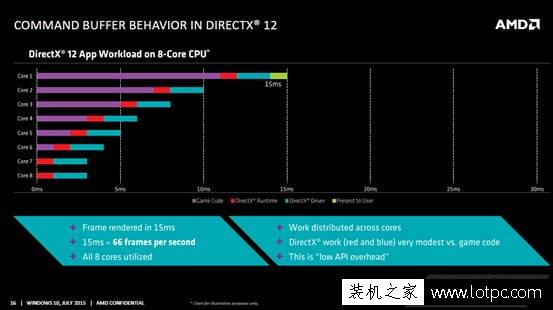
眾所周知,核心數量一直是A家CPU最大的特點,相比Intel保守地增加核心,通過改進架構和設計來提高單個核心性能、從而提高整體核心性能的思路不同;AMD靠多核心的堆砌來獲得性能的加成。在之前的DX版本中,CPU在游戲中所起到的作用是什么呢?舉個例子,就是由CPU書寫“算式”(GPU準備命令列表),然后將其放到GPU計算的書堆里(存儲到緩存區域),接著由GPU進行計算。
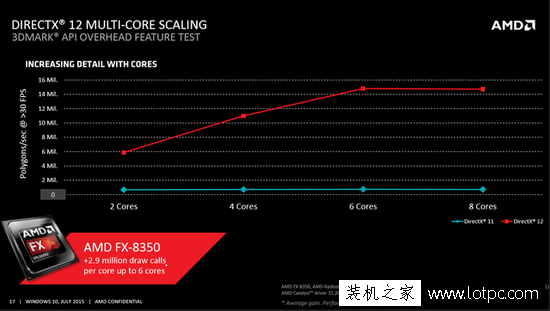
由于曾經的DX版本中,開發者們接觸不到這一過程,也就導致了開發者難以對其進行多核心線程的優化。所以也就是現在很多吧友們所說的游戲“吃單核”的現象。在DX12中,由于底層能夠更加透明地被開放給開發者,使得開發者可以簡單地對這一過程實行優化,就能夠有效地提升多核心的工作效率。根據AMD的說法,在八核心的AMD推土機處理器下,八個核心中的六個都可以得到充分利用。盡管目前這都還是PPT,沒有實踐證明它的效率到底如何,不過從原理上來看,這一說法似乎也并不是完全不靠譜的。
二、多卡互聯下的工作效率提高
AMD現有的Cross Fire交火技術,是AMD花了不少精力開發并優化的,相比NVIDIA的SLI技術,它可以不需要橋接器(最新一代R9 300系顯卡已經可以脫離橋接器),并且不需要授權費,可以降低組建成本。
在以往的DX版本中,如果不是開發者的特別優化,部分游戲甚至都不支持多卡并聯或雙芯顯卡,這對多路GPU的顯卡造成了性能浪費。最令人詬病的是顯存問題,顯存由于采用復制機制,所有并行工作的顯卡中,只能使用顯存最小的那張顯卡作為整個系統的顯存,對大顯存、多路玩家來說,就大大地造成了顯存浪費的情況。
在DX12中,API開始原生地支持了多路顯卡,游戲、驅動開發者可以對多GPU做出優化,將計算任務分配到各個GPU上。甚至是核芯顯卡(因為文章主體是AMD所以這里特指APU的核顯),都可以與獨立顯卡的GPU共同工作,即便這兩者性能差距比較懸殊,不過在這種核顯+獨顯的雙顯卡平臺并且臺式機上沒有方便自由地切換兩者的技術的情況下,核顯也不會被浪費,對消費者來說也算是一件好事。另外,顯存的使用機制由復制變成了疊加,這也就是說可以讓多路顯卡的顯存疊加起來。以往,4張4GB獨立顯卡并聯工作,顯存也只有4GB,在4K游戲的潮流下已經顯得有些捉襟見肘;而現在,4張4GB獨立顯卡并聯工作時,顯存便可以達到16GB,這就解決了顯存浪費的問題。
三、著色器異步計算引擎
在AMD上,這是一項硬件層面上的優化。
什么叫做“著色器”。在早期的GPU上,“著色器”正如其名,是為頂點著色器計算出的三角形進行著色計算的。不過現在,它的功能就更加多樣化了,可以支持各種通用計算。不過這里也就提一下,這其中涉及到GPU工作原理和發展歷史上,由于比較復雜,武林網小編能力有限,如果有興趣的吧友可以查閱更多資料了解。
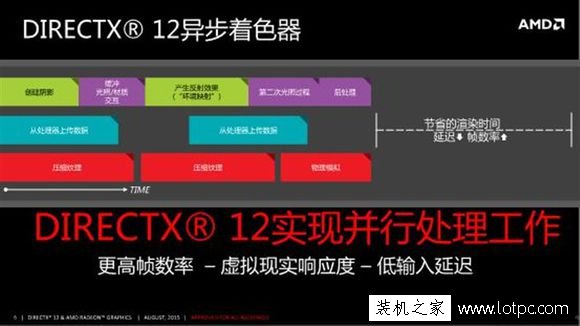
在近代的GPU工作中,GPU運用著色器進行計算的時候,往往將指令進行“排隊”式的工作。指令往往在緩存區中,等待上一組計算完成后,下一組才開始進行計算。并且剛剛提到著色器的功能多樣化之后,功能之間、計算指令“隊伍”之間的切換、等待。在GPU的世界中就造成了較大的延遲。盡管后來通過軟件、硬件的結合優化,廠商們為這個“排隊”式的工作方式進行了改進,使得它擁有了優先,暫停,繼續等稍微智能化一些的做法。提高了一定的工作效率,但這還不夠。
所以,AMD為使用GCN架構的GPU設計了一個名為Asynchronous Compute Engine(異步計算引擎,簡稱ACE)的東西,它可以智能協調GPU上著色器的計算。“排隊”式的工作邏輯被打破,ACE為指令進行有計劃的、有規律的排序。還是提到剛剛的所說的著色器功能多樣化問題,這里舉個例子,假如指令中包含復制、圖形計算、通用計算三種不同的功能。有了ACE后,這些不同的功能會被ACE排好序,同時進入GPU,進行統一計算,并且它還擁有平衡功能,可以靈活地關閉、開啟計算用的單元。減少了以往切換、等待的延遲后,GPU的計算效率自然就提高了。這一點創新武林網小編認為是不錯的。
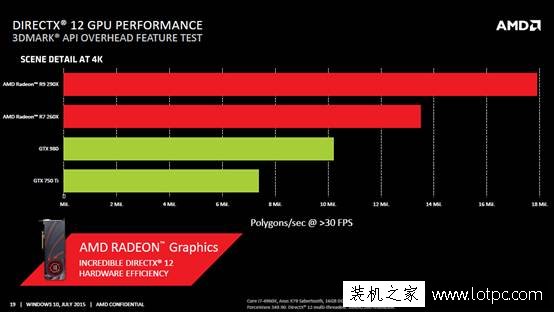
在部分DX12游戲的Benchmark測試中,AMD顯卡的工作效率的確都得到了顯著提升。而NVIDIA方面,在許多Benchmark測試中表現不佳,不過據NVIDIA所說,這是因為對應的驅動和程序尚未到位,將來會解決這個問題。
在DX12時代,以往影響工作效率的問題得到了不小的改善,這一全新的API相信可以成為一座里程碑。至于AMD是否能真正在DX12憑借這三大優化“逆襲”,還需要時間的驗證。讓我們拭目以待。