在Python中使用encode()函數運用指定的編碼方式對字符串進行編碼。
關于編碼的有關知識,本站在《Python中的Unicode編碼格式》一文中進行了詳細介紹,讀者可以通過這篇文章了解有關字符串編碼的問題。
在Python中,每個字符串對象都有encode()函數,該函數將按照用戶指定的編碼方式(如UTF-8,UTF-16等)對字符串對象進行編碼,編碼后返回字符串的字節(Bytes)對象,如未指定編碼格式,該函數默認使用“utf-8”編碼方式。
該函數的語法格式如下所示:
str.encode(encoding = "utf-8", errors = "strict")
語法中,str是待編碼的字符串對象。encoding參數給出編碼方式,默認為“utf-8”,errors 參數給出編碼失敗時的錯誤處理方案,默認為“strict”,即嚴格的錯誤處理方案。

下面這個例子中使用函數各參數的默認值進行編碼,并輸出編碼前后對象的類型。
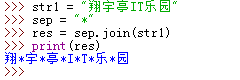
str1 = "武林網VEVB"
str_re1 = str1.encode()
print('原字符串:', str1)
print('原字符串類型:', type(str1))
print('轉換后的形式:', str_re1)
print('轉換后的對象類型:', type(str_re1))
輸出結果形式如下:
原字符串: 武林網VEVB從上面的輸出結果中可以看出,編碼前str1的類型為<class 'str'>,即字符串類型,編碼后的類型為:<class 'bytes'>,即字節類型,同時輸出轉換后的對象我們發現在前面有個字符'b',其表示后面的字符串以字節形式進行存儲。在存儲時,utf-8編碼格式下,漢字占用三個字節,如上面前三個字節(以十六進制形式顯示的):/xe7/xbf/x94,即是字符“翔”的編碼。
原字符串類型: <class 'str'>
轉換后的形式: b'/xe7/xbf/x94/xe5/xae/x87/xe4/xba/xadIT/xe4/xb9/x90/xe5/x9b/xad'
轉換后的對象類型: <class 'bytes'>
encoding用于指定字符串的編碼方式。
Python自帶了很多編解碼器,這些編解碼器要么以C函數的方式實現,要么以映射表的方式存放到詞典中。
這些內置的編解碼器并非都能運用到每一種語言系統中,運用不正確在解碼時可能會出現所謂的亂碼問題。
str1 = "武林網VEVB"
re1 = str1.encode('utf-8')
re2 = str1.encode('gb2312')
re3 = str1.encode('gbk')
re4 = str1.encode('utf-16')
print('utf-8:', re1)
print('gb2312:', re2)
print('gbk:', re3)
print('utf-16:', re4)
運行結果如下所示:
utf-8: b'/xe7/xbf/x94/xe5/xae/x87/xe4/xba/xadIT/xe4/xb9/x90/xe5/x9b/xad'對西文字符也可以使用ASCII編碼方式,如果指定的編碼方式不含相關字符的話,在沒有指定errors參數時,默認會報錯。
gb2312: b'/xcf/xe8/xd3/xee/xcd/xa4IT/xc0/xd6/xd4/xb0'
gbk: b'/xcf/xe8/xd3/xee/xcd/xa4IT/xc0/xd6/xd4/xb0'
utf-16: b'/xff/xfe/xd4/x7f/x87[/xadNI/x00T/x00PN/xedV'
re5 = "I Love China!".encode("ASCII")
print("西文ASCII:", re5)
re6 = "沉痛哀悼袁隆平和吳孟超兩位院士。".encode("ASCII")
print("ASCII運用到中文會出錯:", re6)
輸出結果如下:
西文ASCII: b'I Love China!'從上面的結果可以看出,漢字運用ASCII編碼方式給出UnicodeEncodeError錯誤,意思是說:'ASCII'編解碼器不能對字符串0~15位置的字符進行編碼,序號超出范圍(最大值128)。
Traceback (most recent call last):
File "D:/01Lesson/PY/encode_detail.py", line 21, in <module>
re6 = "沉痛哀悼袁隆平和吳孟超兩位院士。".encode("ASCII")
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-15: ordinal not in range(128)
errors參數的作用是在編碼出現錯誤時給出錯誤的處理方式,默認值為'strict',即出現錯誤時將拋出UnicodeError編碼異常錯誤。UnicodeError包含編碼錯誤的描述內容,其具體內容包括引發異常的編碼方式名稱、錯誤原因、編碼對象出現錯誤的起止字符位置。
其它可以使用的值描述如下:
ignore:忽略不能進行編碼的字符,編碼結果中將不會包含不能進行編碼的字符,且不會再給出任何提示信息。
replace:使用問號(?)替換不能進行編碼的字符。
backslashreplace:使用反斜杠(/)開始的轉義字符序列(/uNNNN)來替代不能實現編碼的字符。
xmlcharrefreplace:使用適當的XML字符引用來替換不能實現編碼的字符。其替換后的字符形如:&#NNNNN。
namereplace:使用反斜杠(/)開始的轉義字符名稱序列(/N{...})來替換未能轉換的字符。此值是在Python3.5中新加入的。
下面給出一些例子來演示各種取值的輸出情況:
str2 = "CRY:沉痛哀悼袁隆平院士和吳孟超院士CRY。"
re8 = str2.encode("ASCII",'ignore')
print("re8=", re8)
re9 = str2.encode("ASCII", 'replace')
print("re9=", re9)
re10 = str2.encode("ASCII", 'backslashreplace')
print("re10=", re10)
re11 = str2.encode("ASCII", 'xmlcharrefreplace')
print("re11=", re11)
re12 = str2.encode("ASCII", 'namereplace')
print('re12=', re12)
re7 = str2.encode("ASCII")
print("re7=", re7)
運行結果如下所示:
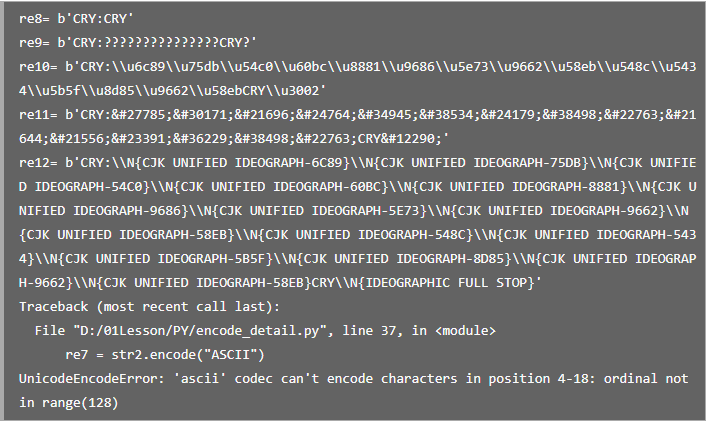
上面例子中最后一個是沒有指定errors參數的情況。其它讀者根據例子中的代碼對照結果觀察每個參數的輸出情況。
以上詳細介紹了Python中字符串處理函數encode()的使用方法,并對其兩個參數encoding和errors進行了全面解釋。
本文(完)
新聞熱點






疑難解答