在R中,可以使用read.table()函數(shù)方便的讀取具有多列表格形式的文件數(shù)據(jù)。文件中的數(shù)據(jù)一般情況,行對(duì)應(yīng)的是樣本,列(字段)對(duì)應(yīng)著相應(yīng)的變量。讀取的數(shù)據(jù)將組織成數(shù)據(jù)框的結(jié)構(gòu)。具體形式和參數(shù)解釋可以參考本站中的這篇文章:R語言中read.table()函數(shù)用法詳解。
本文主要給出一些具體的使用形式。
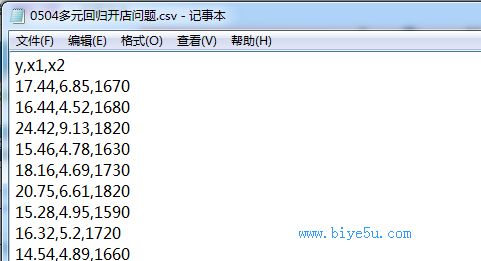
read.table()函數(shù)對(duì)于數(shù)據(jù)文件的擴(kuò)展名并沒有要求。只要數(shù)據(jù)組織時(shí)是按照行和列的形式進(jìn)行組織,且每個(gè)字段的數(shù)據(jù)以某種形式(如空白、逗號(hào)等)進(jìn)行分隔即可。如下面兩個(gè)圖所示的文件格式都可以,甚至是使用其他分隔符分隔的也可以。
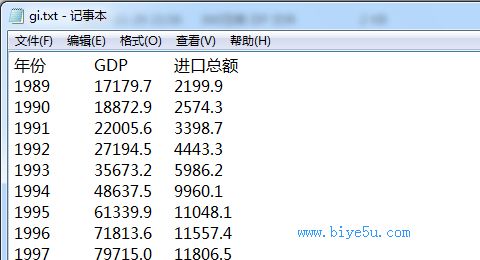
圖1 數(shù)據(jù)文件以空白(tab)進(jìn)行分隔的形式
(1)read.table("gi.txt") #直接給出文件名稱,沒有指定額外的參數(shù)
結(jié)果形式如下:

在沒有給定分隔符時(shí),默認(rèn)以空白分隔(空格或tab制表符),并且可以看出原文件中的標(biāo)題行也作為數(shù)據(jù)進(jìn)行了處理。在沒有給定字段(變量)名稱時(shí),read.table()函數(shù)依次給每列的變量名為v1,v2,...。讀取結(jié)果的第1列為行標(biāo)標(biāo)題。
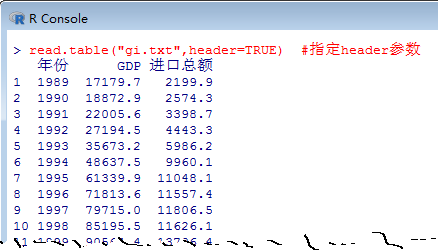
(2)read.table("gi.txt",header=TRUE) #指定header為TRUE,指明原文件中包含變量名(字段名)
讀取結(jié)果如下:
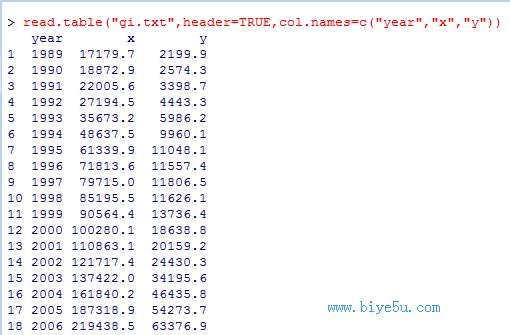
(3)read.table("gi.txt",header=TRUE,col.names=c("year","x","y")) #指定列名的情形
結(jié)果如下:
(4)read.table("0504多元回歸開店問題.csv")
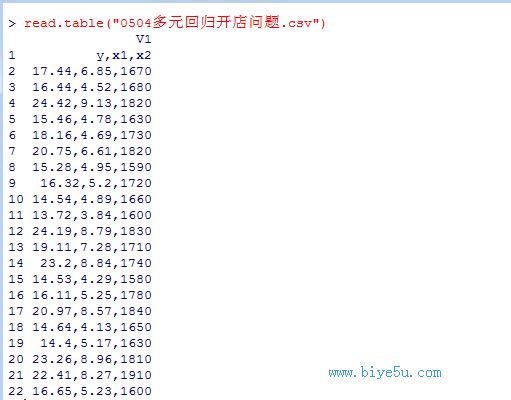
可以看出在以逗號(hào)作為分隔符的文件中,如果不指定數(shù)據(jù)的分隔符,read.table()函數(shù)會(huì)將所有的數(shù)據(jù)理解為一個(gè)字段(變量)下的數(shù)據(jù)。如果要正確讀出原數(shù)據(jù)的格式,可以使用下面的格式:
(5)read.table("0504多元回歸開店問題.csv",header=TRUE,sep=",")

可以看出,這次讀取的數(shù)據(jù)是符合要求的形式。
有時(shí),我們只需要前N行的數(shù)據(jù),這時(shí),可以指定nrows參數(shù)。
(6)read.table("0504多元回歸開店問題.csv",header=TRUE,sep=",",nrows=15) #讀取前15行的數(shù)據(jù)
這樣指定nrows=15,則read.table()函數(shù)只讀取前15行的數(shù)據(jù)(不含標(biāo)題行)。
有時(shí),我們需要忽略前m行的數(shù)據(jù),則可以指定skip參數(shù)。
(7)read.table("0504多元回歸開店問題.csv",header=TRUE,sep=",",skip=5) #忽略前5行的數(shù)據(jù)
這樣指定skip=5后,read.table()函數(shù)將從第6行數(shù)據(jù)讀取。
以上是關(guān)于read.table()函數(shù)經(jīng)常使用的格式。
本文(完)
新聞熱點(diǎn)






疑難解答