異方差性(heteroscedasticity )是相對于同方差而言的。所謂同方差,是為了保證回歸參數估計量具有良好的統計性質,經典線性回歸模型的一個重要假定:總體回歸函數中的隨機誤差項滿足同方差性,即它們都有相同的方差。如果這一假定不滿足,即:隨機誤差項具有不同的方差,則稱線性回歸模型存在異方差性。對于異方差性的回歸問題,需要用到加權最小二乘法。
以下內容轉自:https://zhuanlan.zhihu.com/p/22064801
在往前可以看得見的歷史里,我們漫長的一生中不知道做了多少個回歸,然而并不是每一個回歸都盡如人意,究其原因就很多了,可能是回歸的方程選擇的不好,也可能是參數估計的方法不合適。回歸的本質是在探尋因變量Y和自變量X之間的影響關系國外的論文里常常叫因變量為響應變量,自變量為解釋變量),如何來描述這種相關關系呢?我們可以假設Y的值由兩部分組成,一部分是X能決定的,記為f(X),另一部分由其它眾多未加考慮的因素(如隨機因素)所組成,記為隨機誤差e,并且我們有理由認為E(e)=0.于是我們得到
特別地,當f(X)是線性函數時,我們便得到了眾多回歸組成的王國里最平民也最重要的回歸模型——線性回歸。回歸參數的估計方法最基本的就是最小二乘回歸。盡管長江后浪推前浪,我們有了更多回歸參數的估計方法(詳見優礦量化實驗室),但依然不影響我們對它的喜愛,為了介紹后續的回歸方法,我依然要先把普通最小二乘法的回歸模型擺出來致敬一下:
這里的Y就是n?1的變量觀測向量,X為n?p的已知設計矩陣,β為p?1未知參數向量,e為隨機誤差向量。(這里需要注意的是由于有常數項,所以自變量個數其實是p-1個)
Gauss-Markov假設可以簡寫為E(e)=0,Cov(e)=In,Cov(e,x)=0
普通最小二乘法就是使得殘差平方和最小,通過對矩陣的求導,我們就得到了β的估計Y,在假設下,我們可以證明該估計是β所有線性無偏估計中方差最小的。
與之相關的各種分布和檢驗就不再贅述,社區里也有很多帖子可以學習。既然模型有假設,那么局限性就出來了,我們常常會發現殘差項并不滿足假設,尤其當變量是時間序列時,非平穩性和自相關性常常會造成異方差的問題,那怎么處理異方差的問題呢?方法也挺多的,本帖主要討論一種加權最小二乘估計的方法和機器學習里局部加權線性回歸的方法。(注:此文中的線性回歸是普適的多元線性回歸,所以均用矩陣來表示更方便)
加權最小二乘法其實是廣義最小二乘法的一種特殊情形,而普通最小二乘法也是一種特殊的加權最小二乘法。為了保證知識的完整性,不妨把廣義最小二乘介紹一下:
剛才說到我們的殘差項項不滿足Gauss-Markov假設,那么我們就把假設放寬一些:考慮以下模型:
這里的Σ是我們已知的一個n?n正定對稱矩陣,其中不一定是已知的。也就是說不要求誤差項互不相關了。這里我們的廣義最小二乘法就是使得廣義殘差平方和
最小,最后β的估計為(X)?1Y
實際上,Σ也常常是未知的,但當我們知道Σ的某種形式時,我們可以去估計它。舉個例子,如果出于某種原因,我們樣本的數據來源的地方不一樣,怎樣把他們整合在一起呢,我們可以假設那些來源相同的數據樣本的殘差項方差是一樣的,如:
然后我們再通過迭代的方法(第一步就是普通的最小二乘回歸)去估計,直到相鄰兩次迭代求得的β的估計差不多為止。
從上面可以看出,不論你對自變量和因變量作了何等變換,最終都可以用最小二乘的模型去解決回歸的問題。但普通最小二乘估計里的那些美好的性質,分布和檢驗等在廣義最小二乘里還存在么?還一致么?其實,我們可以通過一些變換,把廣義最小二乘的模型轉換為滿足普通最小二乘法假設的模型,關于這一點,我們以下面的加權最小二乘法舉例說明。
加權最小二乘法,就是對上述的Σ取一種特殊的矩陣--對角陣,而這個對角陣的對角元都是常數,也就是權重的倒數,如下:
表示的就是第i個樣本在回歸里的權重,從上式可以看出來,具有較大權的樣本具有較小的方差,它在回歸問題里顯得更加重要。 不妨用W來表示權重矩陣,那么=W,這時我們用廣義最小二乘的方法來求系數的估計,即最小化廣義殘差平方和
β最后的估計結果為:β^=(WX)?1WY
我們并不滿足于求出廣義的最小二乘估計,我們還要研究它的很多性質,下面上面提過的廣義最小二乘轉換的方法把這個模型轉化為滿足普通最小二乘回歸假設的模型:
首先我們找一下的平方根C,在這個問題里,很容易得到C:
對回歸模型每一項乘以C,得到:
這時候Ce的協方差陣為:
這就是滿足Gauss-Markov假設的普通線性回歸模型了
不妨重新對變量命名:
其中,
感興趣的讀者可以驗證一下,這個新模型用普通最小二乘所估計出來的β和原模型是一樣的,而且線性無偏方差最小的性質和分布,檢驗等都可以用起來了,如及顯著性檢驗等來看擬合的好壞。
局部加權線性回歸是機器學習里的一種經典的方法,彌補了普通線性回歸模型欠擬合或者過擬合的問題。機器學習里分為無監督學習和有監督學習,線性回歸里是屬于有監督的學習。普通的線性回歸屬于參數學習算法(parametric learning algorithm);而局部加權線性回歸屬于非參數學習算法(non-parametric learning algorithm)。所謂參數學習算法它有固定的明確的參數,參數 一旦確定,就不會改變了,我們不需要在保留訓練集中的訓練樣本。而非參數學習算法,每進行一次預測,就需要重新學習一組 , 是變化的,所以需要一直保留訓練樣本。也就是說,當訓練集的容量較大時,非參數學習算法需要占用更多的存儲空間。
上面的話好像不夠直觀,下面我們來直觀地看一下局部加權線性回歸到底是怎么樣的。
局部加權線性回歸就是在給待測點附近的每個點賦予一定的權重,也就是加一個核函數矩陣W,最后需要最小化的目標函數如下:
這就是剛剛的加權最小二乘法,再來看看系數的估計項:
好吧,這就是加權最小二乘法,當然,如果這就是局部加權線性回歸的全部,也不用發明它了,我們接著看。這里出現了一個問題,權重是如何確定的,也就是這個所謂的核函數矩陣的形式,百度了一下,通常使用的都是高斯核,形式如下:
代表的是第i個樣本點,x是我們預測點,對于金融數據來說,完全可以用時間t來衡量,也就是說時間越近的樣本數據越重要,這樣的預測對想研究的對象而言更準確。
介紹到這里似乎沒有體現出機器學習的意思,仔細觀察就會發現K是一個很重要的東西,不信,我們舉個例子來看看:
為了簡單起見,我們就用一元的線性回歸來看看,方便數據可視化。這里我們取一些非線性擬合的數據,因為局部加權線性回歸的優勢就在于處理非線性關系的異方差問題。
看一下我們需要擬合的樣本數據(點擊查看原文代碼):
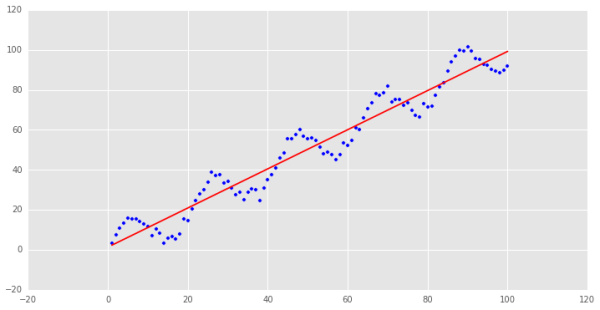
很明顯,這是一個非線性關系的樣本數據,我們先用普通最小二乘回歸來處理這個問題:
y=1.34568655273+0.979532165941x
可以看到,要用直線來擬合非線性關系略有牽強,這個例子還算舉的不錯,金融數據里很多時間序列的關系都是非線性的,回歸的結果往往不好.
下面我們用剛才介紹的局部加權線性回歸來擬合一下這個模型,簡單回顧一下過程:
1.用高斯核函數計算出第i個樣本處,其它所有樣本點的權重W
2.用權重w對第i個樣本作加權線性回歸,得到回歸方程,即擬合的直線方程
3.用剛才得到的經驗回歸直線計算出xi處的估計值y^i
4.重復一至三步,得到每個樣本點的估計值
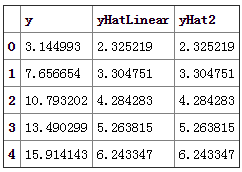
這里作加權線性回歸時,我使用的是把加權最小二乘轉換為普通最小二乘的方法,也就是本帖第二部分內容,網上的做法大多是直接用上面的公式算出β的估計值。
剛才說到,k是一個很關鍵的參數,我們從高斯函數的形式可以看出,k取非常大的時候,每個樣本點的權重都趨近于1,我們可以先取k很大,檢驗一下是否正確
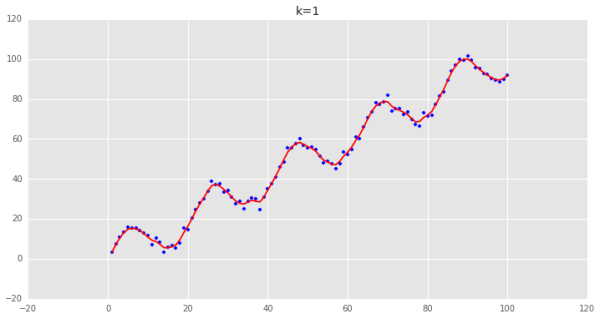
可以看到用普通最小二乘估計出來的值和我們用局部加權估計出來的值非常的一致,說明邏輯是對的。 下面調整一下k的值,來看看各種k值下的擬合狀況:
可以看到,當k越小時,擬合的效果越好,但是我們擬合的目的在于預測,需要避免過擬合的問題,這時候需要做Bias/Variance Trade-off:
Cross Validation可以幫助我們做Bias/Variance Trade-off:
一般的Validation就是把數據分為隨機的兩部分一部分做訓練,一部分作驗證。還有leave-one-out validation,k-fold Cross Validation等方法。
訓練的目的是為了讓訓練誤差盡量減小,同時也要注意模型的自由度(參數個數),避免測試誤差很大。
訓練誤差一般用MSE來衡量:
比如在我們這個簡單的例子里,如果要對之后的數據進行預測,就需要通過Validation選擇參數k的大小,再對離需要預測的點最近的點做加權線性回歸去估計那個點的值。新聞熱點






疑難解答
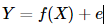 特別地,當f(X)是線性函數時,我們便得到了眾多回歸組成的王國里最平民也最重要的回歸模型——線性回歸。回歸參數的估計方法最基本的就是最小二乘回歸。盡管長江后浪推前浪,我們有了更多回歸參數的估計方法(詳見優礦量化實驗室),但依然不影響我們對它的喜愛,為了介紹后續的回歸方法,我依然要先把普通最小二乘法的回歸模型擺出來致敬一下:
特別地,當f(X)是線性函數時,我們便得到了眾多回歸組成的王國里最平民也最重要的回歸模型——線性回歸。回歸參數的估計方法最基本的就是最小二乘回歸。盡管長江后浪推前浪,我們有了更多回歸參數的估計方法(詳見優礦量化實驗室),但依然不影響我們對它的喜愛,為了介紹后續的回歸方法,我依然要先把普通最小二乘法的回歸模型擺出來致敬一下: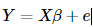 這里的Y就是n?1的變量觀測向量,X為n?p的已知設計矩陣,β為p?1未知參數向量,e為隨機誤差向量。(這里需要注意的是由于有常數項,所以自變量個數其實是p-1個)
這里的Y就是n?1的變量觀測向量,X為n?p的已知設計矩陣,β為p?1未知參數向量,e為隨機誤差向量。(這里需要注意的是由于有常數項,所以自變量個數其實是p-1個)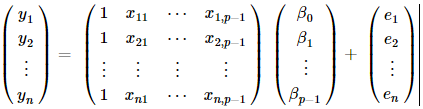
 In,Cov(e,x)=0
In,Cov(e,x)=0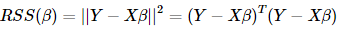 最小,通過對矩陣的求導,我們就得到了β的估計
最小,通過對矩陣的求導,我們就得到了β的估計
 Y,在假設下,我們可以證明該估計是β所有線性無偏估計中方差最小的。
Y,在假設下,我們可以證明該估計是β所有線性無偏估計中方差最小的。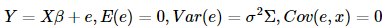 這里的Σ是我們已知的一個n?n正定對稱矩陣,其中
這里的Σ是我們已知的一個n?n正定對稱矩陣,其中 最小,最后β的估計為(
最小,最后β的估計為( X)?1
X)?1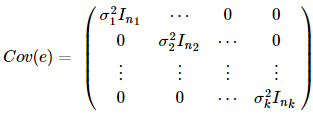 然后我們再通過迭代的方法(第一步就是普通的最小二乘回歸)去估計
然后我們再通過迭代的方法(第一步就是普通的最小二乘回歸)去估計 ,直到相鄰兩次迭代求得的β的估計差不多為止。
,直到相鄰兩次迭代求得的β的估計差不多為止。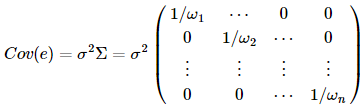
 表示的就是第i個樣本在回歸里的權重,從上式可以看出來,具有較大權的樣本具有較小的方差,它在回歸問題里顯得更加重要。 不妨用W來表示權重矩陣,那么
表示的就是第i個樣本在回歸里的權重,從上式可以看出來,具有較大權的樣本具有較小的方差,它在回歸問題里顯得更加重要。 不妨用W來表示權重矩陣,那么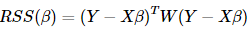 β最后的估計結果為:β^=(
β最后的估計結果為:β^=(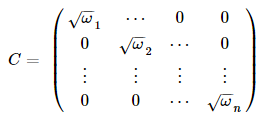 對回歸模型每一項乘以C,得到:
對回歸模型每一項乘以C,得到: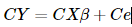 這時候Ce的協方差陣為:
這時候Ce的協方差陣為: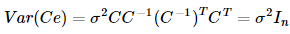 這就是滿足Gauss-Markov假設的普通線性回歸模型了
這就是滿足Gauss-Markov假設的普通線性回歸模型了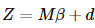 其中,
其中,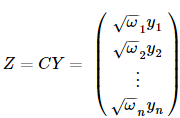
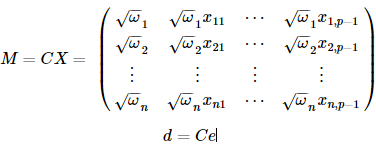 感興趣的讀者可以驗證一下,這個新模型用普通最小二乘所估計出來的β和原模型是一樣的,而且線性無偏方差最小的性質和分布,檢驗等都可以用起來了,如
感興趣的讀者可以驗證一下,這個新模型用普通最小二乘所估計出來的β和原模型是一樣的,而且線性無偏方差最小的性質和分布,檢驗等都可以用起來了,如 及顯著性檢驗等來看擬合的好壞。
及顯著性檢驗等來看擬合的好壞。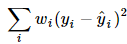 這就是剛剛的加權最小二乘法,再來看看系數的估計項:
這就是剛剛的加權最小二乘法,再來看看系數的估計項: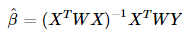
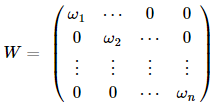 好吧,這就是加權最小二乘法,當然,如果這就是局部加權線性回歸的全部,也不用發明它了,我們接著看。這里出現了一個問題,權重是如何確定的,也就是這個所謂的核函數矩陣的形式,百度了一下,通常使用的都是高斯核,形式如下:
好吧,這就是加權最小二乘法,當然,如果這就是局部加權線性回歸的全部,也不用發明它了,我們接著看。這里出現了一個問題,權重是如何確定的,也就是這個所謂的核函數矩陣的形式,百度了一下,通常使用的都是高斯核,形式如下: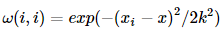
 代表的是第i個樣本點,x是我們預測點,對于金融數據來說,完全可以用時間t來衡量,也就是說時間越近的樣本數據越重要,這樣的預測對想研究的對象而言更準確。
代表的是第i個樣本點,x是我們預測點,對于金融數據來說,完全可以用時間t來衡量,也就是說時間越近的樣本數據越重要,這樣的預測對想研究的對象而言更準確。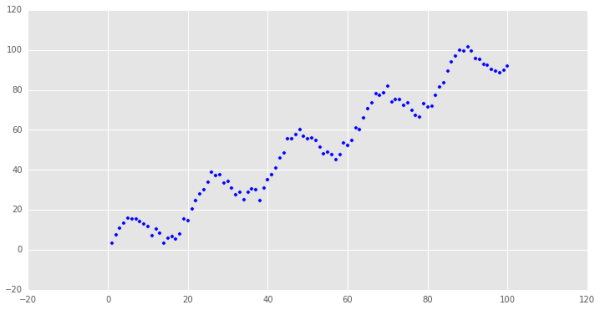 很明顯,這是一個非線性關系的樣本數據,我們先用普通最小二乘回歸來處理這個問題:
很明顯,這是一個非線性關系的樣本數據,我們先用普通最小二乘回歸來處理這個問題: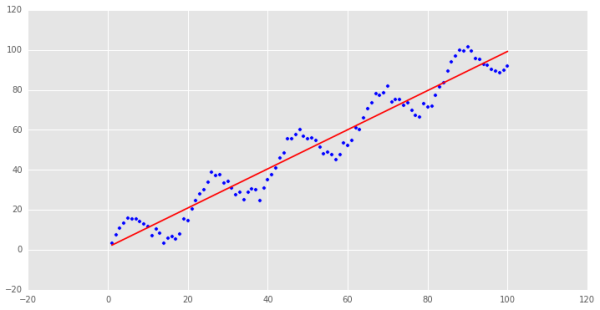
 可以看到用普通最小二乘估計出來的值和我們用局部加權估計出來的值非常的一致,說明邏輯是對的。 下面調整一下k的值,來看看各種k值下的擬合狀況:
可以看到用普通最小二乘估計出來的值和我們用局部加權估計出來的值非常的一致,說明邏輯是對的。 下面調整一下k的值,來看看各種k值下的擬合狀況: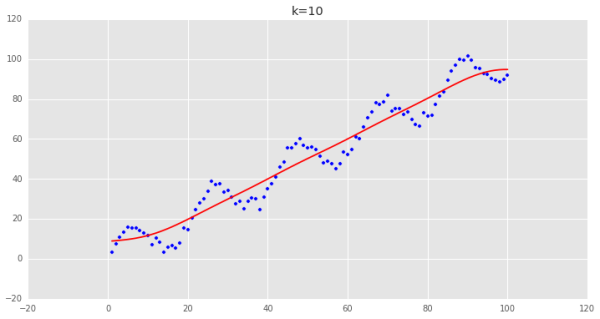
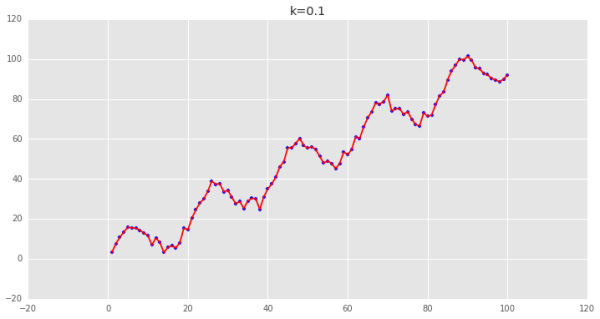 可以看到,當k越小時,擬合的效果越好,但是我們擬合的目的在于預測,需要避免過擬合的問題,這時候需要做Bias/Variance Trade-off:
可以看到,當k越小時,擬合的效果越好,但是我們擬合的目的在于預測,需要避免過擬合的問題,這時候需要做Bias/Variance Trade-off: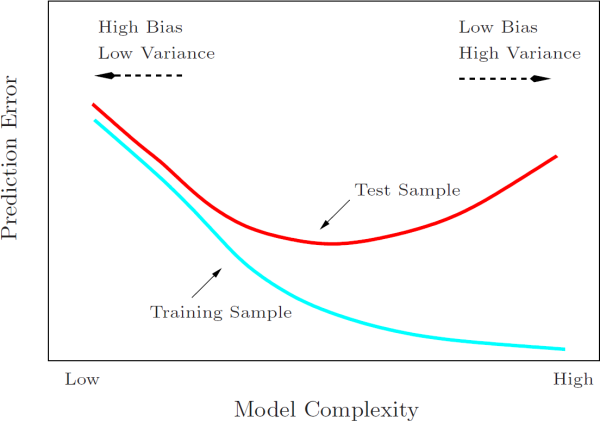
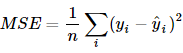 比如在我們這個簡單的例子里,如果要對之后的數據進行預測,就需要通過Validation選擇參數k的大小,再對離需要預測的點最近的點做加權線性回歸去估計那個點的值。
比如在我們這個簡單的例子里,如果要對之后的數據進行預測,就需要通過Validation選擇參數k的大小,再對離需要預測的點最近的點做加權線性回歸去估計那個點的值。












