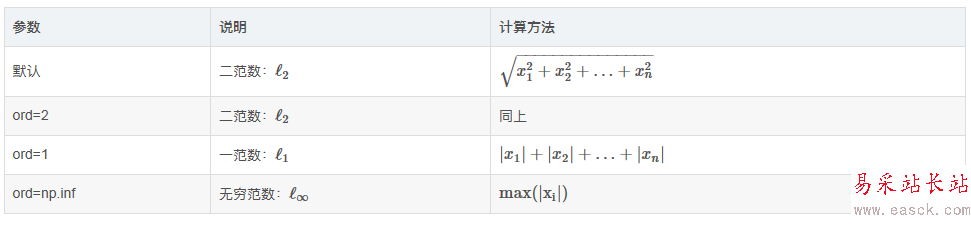
接下來準備用糗百做一個爬蟲的小例子。
但是在這之前,先詳細的整理一下Python中的正則表達式的相關內容。
正則表達式在Python爬蟲中的作用就像是老師點名時用的花名冊一樣,是必不可少的神兵利器。
一、 正則表達式基礎
1.1.概念介紹
正則表達式是用于處理字符串的強大工具,它并不是Python的一部分。
其他編程語言中也有正則表達式的概念,區(qū)別只在于不同的編程語言實現(xiàn)支持的語法數(shù)量不同。
它擁有自己獨特的語法以及一個獨立的處理引擎,在提供了正則表達式的語言里,正則表達式的語法都是一樣的。
下圖展示了使用正則表達式進行匹配的流程:
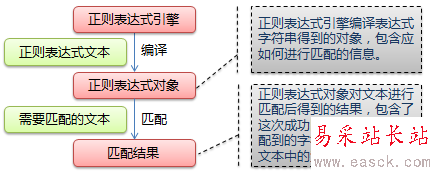
正則表達式的大致匹配過程是:
1.依次拿出表達式和文本中的字符比較,
2.如果每一個字符都能匹配,則匹配成功;一旦有匹配不成功的字符則匹配失敗。
3.如果表達式中有量詞或邊界,這個過程會稍微有一些不同。
下圖列出了Python支持的正則表達式元字符和語法:

1.2. 數(shù)量詞的貪婪模式與非貪婪模式
正則表達式通常用于在文本中查找匹配的字符串。
貪婪模式,總是嘗試匹配盡可能多的字符;
非貪婪模式則相反,總是嘗試匹配盡可能少的字符。
Python里數(shù)量詞默認是貪婪的。
例如:正則表達式"ab*"如果用于查找"abbbc",將找到"abbb"。
而如果使用非貪婪的數(shù)量詞"ab*?",將找到"a"。
1.3. 反斜杠的問題
與大多數(shù)編程語言相同,正則表達式里使用"/"作為轉義字符,這就可能造成反斜杠困擾。
假如你需要匹配文本中的字符"/",那么使用編程語言表示的正則表達式里將需要4個反斜杠"http:////":
第一個和第三個用于在編程語言里將第二個和第四個轉義成反斜杠,
轉換成兩個反斜杠//后再在正則表達式里轉義成一個反斜杠用來匹配反斜杠/。
這樣顯然是非常麻煩的。
Python里的原生字符串很好地解決了這個問題,這個例子中的正則表達式可以使用r"http://"表示。
同樣,匹配一個數(shù)字的"http://d"可以寫成r"/d"。
有了原生字符串,媽媽再也不用擔心我的反斜杠問題~
二、 介紹re模塊
2.1. Compile
Python通過re模塊提供對正則表達式的支持。
使用re的一般步驟是:
Step1:先將正則表達式的字符串形式編譯為Pattern實例。
Step2:然后使用Pattern實例處理文本并獲得匹配結果(一個Match實例)。
Step3:最后使用Match實例獲得信息,進行其他的操作。
我們新建一個re01.py來試驗一下re的應用:
新聞熱點




疑難解答