前言
介紹Spark SQL的JSON支持,這是我們在Databricks中開發的一個功能,可以在Spark中更容易查詢和創建JSON數據。隨著網絡和移動應用程序的普及,JSON已經成為Web服務API以及長期存儲的常用的交換格式。使用現有的工具,用戶通常會使用復雜的管道來在分析系統中讀取和寫入JSON數據集。在Apache Spark 1.1中發布Spark SQL的JSON支持,在Apache Spark 1.2中增強,極大地簡化了使用JSON數據的端到端體驗。
很多時候,比如用structure streaming消費kafka數據,默認可能是得到key,value字段,key是偏移量,value是一個byte數組。很可能value其實是一個Json字符串。這個時候我們該如何用SQL操作這個json里的東西呢?另外,如果我處理完的數據,我想寫入到kafka,但是我想把整條記錄作為json格式寫入到Kafka,又該怎么寫這個SQL呢?
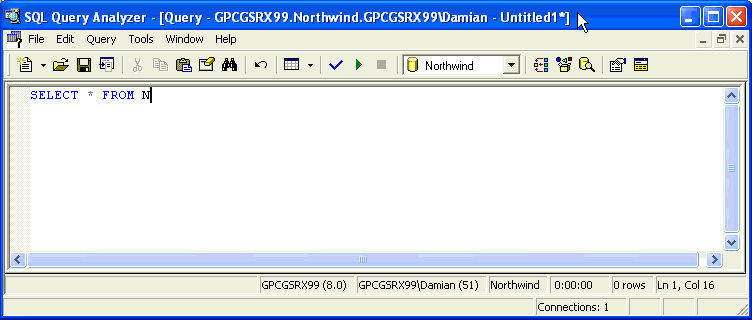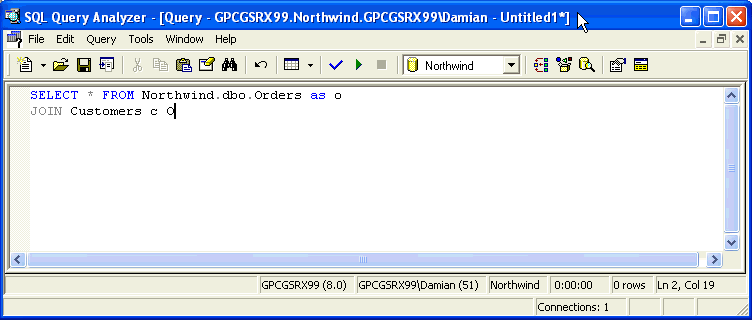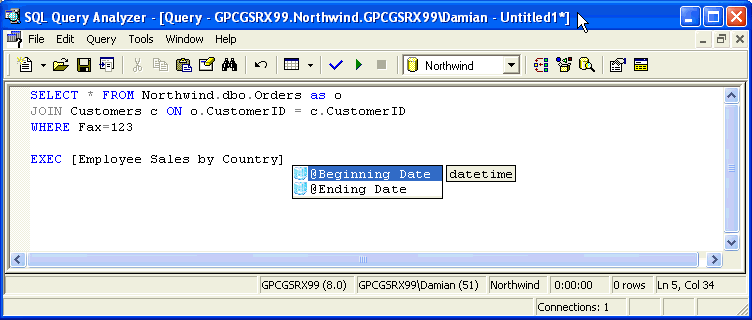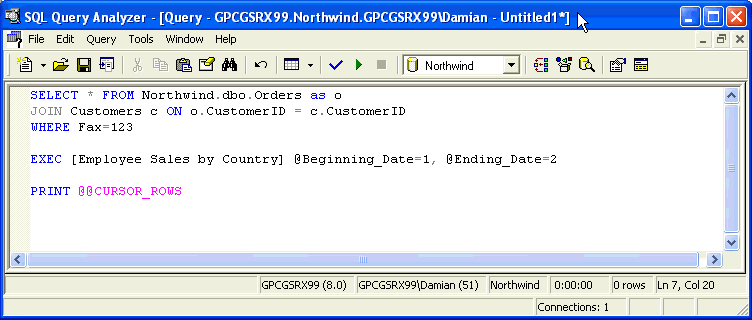
get_json_object
第一個就是get_json_object,具體用法如下:
select get_json_object('{"k": "foo", "v": 1.0}','$.k') as k需要給定get_json_object 一個json字段名(或者字符串),然后通過類似jsonPath的方式去拿具體的值。
這個方法其實有點麻煩,如果要提取里面的是個字段,我就要寫是個類似的東西,很復雜。
from_json
具體用法如下:
select a.k from (select from_json('{"k": "foo", "v": 1.0}','k STRING, v STRING',map("","")) as a)這個方法可以給json定義一個Schema,這樣在使用時,就可以直接使用a.k這種方式了,會簡化很多。
to_json
該方法可以把對應字段轉化為json字符串,比如:
select to_json(struct(*)) AS value
可以把所有字段轉化為json字符串,然后表示成value字段,接著你就可以把value字段寫入Kafka了。是不是很簡單。
處理具有大量字段的JSON數據集
JSON數據通常是半結構化、非固定結構的。將來,我們將擴展Spark SQL對JSON支持,以處理數據集中的每個對象可能具有相當不同的結構的情況。例如,考慮使用JSON字段來保存表示HTTP標頭的鍵/值對的數據集。每個記錄可能會引入新的標題類型,并為每個記錄使用一個不同的列將產生一個非常寬的模式。我們計劃支持自動檢測這種情況,而是使用map類型。因此,每行可以包含Map,使得能夠查詢其鍵/值對。這樣,Spark SQL將處理具有更少結構的JSON數據集,推動了基于SQL的系統可以處理的那種查詢的邊界。
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作具有一定的參考學習價值,如果有疑問大家可以留言交流,謝謝大家對武林網的支持。
新聞熱點




疑難解答