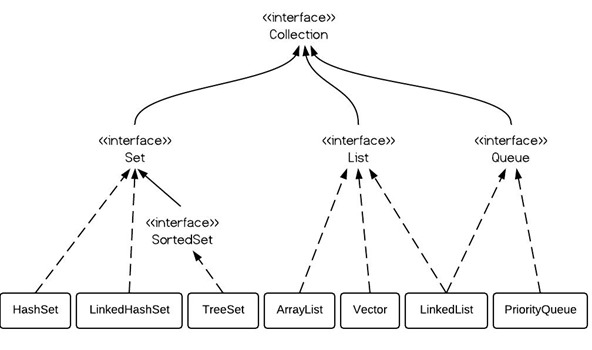
Collection單列集合
(接口)List: 實現類 ArrayList LinkedList Vector (接口)Set: 實現類 HashSet TreeSet LinkedHashSetMap雙列集合
(接口)map: 實現類 HashMap Hashtable TreeMap PRopertiesArrayList、Vector、HashMap、HashSet的默認初始容量、加載因子、擴容增量? http://www.cnblogs.com/xiezie/p/5511840.html
Collections
java.util.Collections是集合類的一個工具類/幫助類,此類不能實例化,其中提供了一系列靜態方法,用于對集合中元素進行排序、搜索以及線程安全等各種操作。常用方法 sort 排序max/min 求最值fill 填充reverse 反轉代碼
Integer[] arr = new Integer[] { 2, 1, 3 }; List<Integer> list1 = Arrays.asList(arr);List<Integer> list2 = new ArrayList<>(list1);list2.add(4);System.out.println(list2);//[2, 1, 3, 4]Collections.reverse(list2);System.out.println(list2);//[4, 3, 1, 2]System.out.println(Collections.max(list2));//4System.out.println(Collections.min(list2));//1Collections.sort(list2);System.out.println(list2);//[1, 2, 3, 4]Collections.fill(list2, 2);System.out.println(list2);//[2, 2, 2, 2]ArrayList實現類
ArrayList 是 List 接口的典型實現類,本質上,ArrayList是對象引用的一個變長數組。List 接口的大小可變數組的實現。實現了所有可選列表操作,并允許包括 null 。默認初始容量為10。當集合容量不夠時,默認是增加原來集合元素個數的一半特點: 底層是數組結構;適合搜索,不適合增刪改(空間是連續的); 版本較新,線程不安全,不同步,效率比較高。構造方法摘要 :
ArrayList() 構造一個初始容量為 10 的空列表。 ArrayList(Collection<? extends E> c) 構造一個包含指定 collection 的元素的列表,這些元素是按照該 collection 的迭代器返回它們的順序排列的。 ArrayList(int initialCapacity) 構造一個具有指定初始容量的空列表和數組的轉換
調用Arrays的asList(Abject o)方法代碼
Integer[] arr = new Integer[] { 1, 2, 3 };List<Integer> list1 = Arrays.asList(arr);// list1.add("c");//java.lang.UnsupportedOperationExceptionList<Integer> list2 = new ArrayList<>(list1);list2.add(4);//可以使用java.lang.UnsupportedOperationException是不支持功能異常,常常出現在使用Arrays.asList()后調用add,remove這些方法時。 這是由于: Arrays.asList() 返回java.util.Arrays
LinkedList
對于頻繁的插入或刪除元素的操作,建議使用LinkedList類,效率較高。特點: 底層采用的是鏈表結構適合做增刪改,不適合搜索(空間是不連續)特有的方法
將元素插入列表開頭:addFirst(E e)將元素插入列表結尾:addLast(E e)返回此列表的第一個元素:getFirst() 返回此列表的最后一個元素:getLast() 移除并返回此列表第一個元素: removeFirst()移除并返回此列表的最后一個元素: removeLast()//等等特殊方法LinkedList內部有個內部類Node,這樣
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; }}LinkedList:雙向鏈表除了保存數據,還定義了兩個變量:prev變量記錄前一個元素的位置next變量記錄后一個元素的位置刪除元素時,只需改變前后兩個元素的prev和next值。Vector
古老的實現類、線程安全的,但效率要低于ArrayList。特點: 版本較老,線程安全的,同步的,效率比較低底層采用的是數組結構比較
ArrayList和Vector 的對比 特點 底層:數組結構 ArrayList 線程不同步,效率高,不安全(單線程訪問時) Vector 線程同步,效率低,安全(多線程訪問時)ArrayList和LinkedList的對比| 類 | 底層結構 | 常用方法 | 特點 |
|---|---|---|---|
| ArrayList | 數組 | List接口中的方法 | 搜索速度比較快,而增刪改較慢(空間是連續的) |
| LinkedList | 鏈表 | List接口中的方法和特有方法 | 增刪改速度比較快,而搜索比較慢(空間是不連續的) |
HashSet
HashSet是Set接口的典型實現,大多數情況使用Set集合時都使用這個實現類。HashSet按Hash算法來存儲集合中的元素,因此具有很好的存取和查找性能。當向HashSet集合中添加元素時,HashSet會調用該對象的HashCode()方法來得到這個對象的hashCode值,然后根據hashCode值決定該對象在HashSet 中的存儲位置。 2)特點: 底層采用哈希表結構,是無序的;HashSet**線程不安全;**集合元素可以為null。3)為什么用哈希算法來存儲集合中的元素?
因為Set集合想要保證不重復性,因此每一個對象放入到集合中,就意味著要和集合中的每一個元素都比較一次,那么這樣的效率極低,所以用哈希算法來存儲,因為hashCode不相等的兩個對象肯定是兩個不相同的對象(散列函數的結論),如果HashCode相同,那就再判斷equals方法,這樣就大大減少了工作量,提高了效率。4)對于存放在Set容器中的對象,對應的類一定要寫equals()和hashCode(Object obj)方法,以實現對象相等規則。
5)重寫hashCode方法的基本原則: 在程序運行時,同一個對象多次調用hashCode()方法應該返回相同的值;當兩個對象的equals方法比較返回true時,這兩個對象的hashCode()方法返回值也應該相同。對象中用作equals方法比較的屬性,都應該用來計算hashCode值。6) 不同對象的哈希值有可能一樣如果兩個對象的equals 比較結果為true,則哈希值肯定一樣兩個對象的哈希值一樣,但equals結果不一定為trueLinkedHashSet
1)LinkedHashSet是HaseSet的子類。是根據元素的hashCode值來決定元素的存儲位置,但同時使用鏈表維護元素的次序,使得元素看起來像是插入順序保證的。2)特點 底層是鏈表和哈希表的雙實現;存入和取出的順序一致;不允許元素重復。TreeSet
1)TreeSet 是 SortedSet 接口的實現類,TreeSet 可以確保集合元素處于排序狀態。2)特點: 底層采用二叉樹結構,實現對元素的排序功能元素不能重復3)TreeSet有兩種排序方法:自然排序和定制排序
要添加的元素類型自己實現Comparable,重寫compareTo方法在創建TreeSet對象時,指定Comparator接口對象,重寫compare方法4)特殊方法:
first(): 返回此 set 中當前第一個(最低)元素。 floor(E e) : 返回此 set 中小于等于給定元素的最大元素;如果不存在這樣的元素,則返回 null。last(): 返回此 set 中當前最后一個(最高)元素。 lower(E e) : 返回此 set 中嚴格小于給定元素的最大元素;如果不存在這樣的元素,則返回 null。 等等特點
Map與Collection并列存在。用于保存具有映射關系的數據:Key-Value ;Map中的key和value都可以是任何引用類型的數據,value可以重復; Map中的key用Set來存放,不允許重復,即作為map的key類型,需重寫hashCode()和equals()方法;常用String類作為Map的鍵,key和value之間存在一對一的關系,即通過指定的key能找到唯一、確定的value值。常用方法: clear():從此映射中移除所有映射關系(可選操作)boolean containsKey(Object key): 如果此映射包含指定鍵的映射關系,則返回 true。boolean containsValue(Object value): 如果此映射將一個或多個鍵映射到指定值,則返回 true。 entrySet(): 返回此映射中包含的映射關系的 Set 視圖。boolean equals(Object o): 比較指定的對象與此映射是否相等。V get(Object key) : 返回指定鍵所映射的值;如果此映射不包含該鍵的映射關系,則返回 null。 int hashCode(): 返回此映射的哈希碼值。boolean isEmpty() : 如果此映射未包含鍵-值映射關系,則返回 true。Set keySet() : 返回此映射中包含的鍵的 Set 視圖。V put(K key, V value) : 將指定的值與此映射中的指定鍵關聯(可選操作)。void putAll( m) : 從指定映射中將所有映射關系復制到此映射中(可選操作)。 V remove(Object key): 如果存在一個鍵的映射關系,則將其從此映射中移除(可選操作)。int size(): 返回此映射中的鍵-值映射關系數。Collection values() : 返回此映射中包含的值的 Collection 視圖。Map繼承樹
 Map常用的實現類:HashMap、TreeMap和Properties。
Map常用的實現類:HashMap、TreeMap和Properties。HashMap
1)HashMap是Map接口使用頻率最高的類,允許null值和null鍵,與HashSet一樣,不保證映射順序。2)HashMap**判斷兩個key相等的標準是**:兩個key通過equals()方法返回true,并且hashCode值也相同。3)HashMap**判斷兩個value相等的標準是**:兩個value通過equals()方法返回true。4)特點:
底層是哈希表結構,鍵是無序的;一般要重寫 hashcode和equals方法;版本比較新,線程不安全、不同步的、效率高,允許null鍵null值。5)LinkedHashMap是HashMap的子類,與LinkedHashSet類似,LinkedHashMap可以維護Map的迭代順序:迭代順序與key-value對的插入順序一致,
TreeMap
1)TreeMap存儲key-value對時,需要根據key-value對進行排序。TreeMap可以保證所有的key-value對處于有序狀態。2)TreeMap的key的排序: 自然排序:TreeMap的key必須實現Comparable接口,而且所有的key應該是同一個類的對象,否則將會拋出ClassCastException;定制排序:創建TreeMap時,傳入一個Comparator對象,該對象負責對key進行排序,此時不需要Map的key實現Comparable接口。3)TreeMap判斷兩個key相等的標準:兩個ket通過compareTo()方法或Compare()方法返回0;4)若使用自定義類作為TreeMap的key,屬性類需要重寫equals()和hashCode()方法,且equals()方法返回true時,compareTo()返回0。5)特點: 底層是二叉樹,可以實現對鍵排序HashTable
1)HashTable是個古老的Map實現類,線程安全。2)與HashMap不同,HashTable不允許出現null作為key和value。3)與HashMap一樣,HashTable也不能保證key-value對的順序。4)HashTable判斷兩個key相等、兩個value相等的標準與HashMap相同。Properties
1)Properties是HashTable的子類,該類用于處理屬性文件。2)特點: 用于讀取和寫入屬性文件(Xxx.properties)3)屬性文件格式要求 鍵值對;鍵和值都是String類型。4)常用方法 getProperty(String key): 獲取屬性 setProperty(String key,String value):設置屬性load(InputStream inStream) :加載屬性文件的數據到Properties集合中list(PrintStream out) :打印Properties集合中的元素到指定設備上store(OutputStream out, String comments) :將集合中的內容存儲到文件中Iterable
Iterator是迭代器類,而Iterable是為了只要實現該接口就可以使用foreach,進行迭代.Iterable中封裝了Iterator接口,只要實現了Iterable接口的類,就可以使用Iterator迭代器了。這個迭代器是用接口定義的 iterator方法提供的。也就是iterator方法需要返回一個Iterator對象。集合Collection、List、Set都是Iterable的實現類,所以他們及其他們的子類都可以使用foreach進行迭代。
//Iterable JDK源碼//可以通過成員內部類,方法內部類,甚至匿名內部類去實現Iteratorpublic interface Iterable<T>{ Iterator<T> iterator();}Iterator
包含3個方法: hasNext(), next() , remove()。一開始迭代器在所有元素的左邊,調用next()之后,迭代器移到第一個和第二個元素之間,next()方法返回迭代器剛剛經過的元素。hasNext()若返回True,則表明接下來還有元素,迭代器不在尾部。remove()方法必須和next方法一起使用,功能是去除剛剛next方法返回的元素。為什么一定要去實現Iterable這個接口呢? 為什么不直接實現Iterator接口呢?
Collection接口實現了Iterable接口,但并不直接實現Iterator接口。因為Iterator接口的核心方法next()或者hasNext(),是依賴于迭代器的當前迭代位置的。如果Collection直接實現Iterator接口,勢必導致集合對象中包含當前迭代位置的數據(指針)。當集合在不同方法間被傳遞時,由于當前迭代位置不可預置,那么next()方法的結果會變成不可預知。而Iterable則不然,每次調用都會返回一個從頭開始計數的迭代器。多個迭代器是互不干擾的。使用迭代器Iterator的方式。
語法
Iterator iter = coll.iterator();while(iter.hasNext()){ Object obj = iterm.next();} 遍歷過程中,不允許做集合元素的增刪改的,只能使用Iterator本身的remove方法做刪除。使用增強for循環的方式。
語法
for(元素類型 元素名:集合或數組名){ 訪問 元素名 syso(obj);}新聞熱點






疑難解答