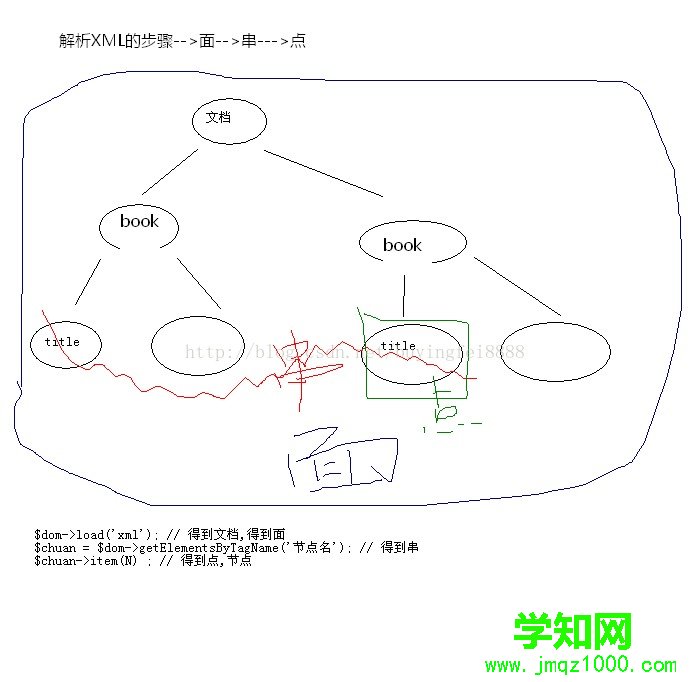
為什么要使用XPATH,上一篇博客查詢越靠近下面單詞,時間會越長,超過2s就不太好了,XPAth就是用來提高解析XML速度的。還可以解析html,效率也是不錯的!
分別查詢下列信息

代碼:
<?php// 詳細學習可以參考w3cschool 構造一個XPATH查詢器$xml = new DOMDocument('1.0','utf-8');$xml->load('book.xml');$xpath = new DOMXPATH($xml);/*$sql = 'xxx'; // 路徑表達式$xpath->query($sql);*//*xpath的路徑表達式如何寫?xpath是從根節點到某個節點聲經過的路徑*/// 查詢book.xml下面的每本書的title// /bookstore/book/title/*$sql = '/bookstore/book/title';$rs = $xpath->query($sql);print_r($rs);echo $rs->item(1)->nodeValue;*/// 查詢book.xml下面book節點的下面的第2個title節點,哪來的第2個title節點? 這樣寫是不對的/*$sql = '/bookstore/book/title[2]';$rs = $xpath->query($sql);print_r($rs->length);*/// 查詢bookestore下面的第2本書下面的title節點./*$sql = '/bookstore/book[2]/title';$rs = $xpath->query($sql);print_r($rs->item(0)->nodeValue);*/// 查詢bookstore下面的book節點并且價格>40元/*$sql = '/bookstore/book[price>40]/title';$rs = $xpath->query($sql);echo $rs->item(0)->nodeValue;*/// 查詢俠客行的價格// /bookstore/下面的book,且title=='俠客行'的書的價格$sql = '/bookstore/book[title="俠客行"]/price';$rs = $xpath->query($sql);echo $rs->item(0)->nodeValue;
<?php$xml = new DOMDocument('1.0','utf-8');$xml->load('book.xml');$xpath = new DOMXPATH($xml);$sql = '/bookstore/book[last()]/title';$rs = $xpath->query($sql);// 只能查到書名的title//echo $rs->item(0)->nodeValue; // 思考 ,如何查詢所有的title,不考慮層次關系?$sql = '/title'; // 這樣不行,這樣查的是根節點下的title,而根節點下沒有title/*/a/b,這說明,a,b就是父子關系,而如果用/a//b,這樣說明a只是b的祖先就行,忽略了層次*/// 不分層次,查出所有的title/*$sql = '//title';foreach($xpath->query($sql) as $v) { echo $v->nodeValue,'<br />';}*//*$sql = '//title[2]'; // 這樣又理解成<title>a</title><title>b</title>,查詢所有相鄰的title節點,且第2個foreach($xpath->query($sql) as $v) { echo $v->nodeValue,'<br />';}*/<?php// 接收單詞并解析XML查詢相應的單詞$word = isset($_GET['word'])?trim($_GET['word']):'';if(empty($word)) { exit('你想查啥?');}// 解析XML并查詢$xml = new DOMDocument('1.0','utf-8');$xml->load('./dict.xml');/*$namelist = $xml->getElementsByTagName('name');$isfind = false;foreach($namelist as $v) { if($v->nodeValue == $word) { //print_r($v); echo $word,'<br />'; echo '意思:',$v->nextSibling->nodeValue,'<br />'; echo '例句:',$v->nextSibling->nextSibling->nodeValue,'<br />'; $isfind = true; break; }}if(!$isfind) { echo 'sorry';}*/// 接下來用xpath來查詢詞典$xpath = new DOMXpath($xml);// 查詢/dict下的word,且name=$word的節點下面的/name節點$sql = '/dict/word[name="' . $word . '"]/name'; //echo $sql;$words = $xpath->query($sql);if($words->length == 0) { echo 'sorry'; exit;}// 查到了$name = $words->item(0);echo $word,'<br />';echo '意思:',$name->nextSibling->nodeValue,'<br />';echo '例句:',$name->nextSibling->nextSibling->nodeValue,'<br />';<?php/***====筆記部分====xpath是根據DOM標準來查詢,html也是DOM,也能查,豈只是xml***/$html = new DOMDocument('1.0','utf-8');$html->loadhtmlfile('dict.html');$xpath = new DOMXPATH($html);$sql = '/html/body/h4';echo $xpath->query($sql)->item(0)->nodeValue,'<br />';// 查詢id="abc"的div節點$sql = '//div[@id="abc"]';echo $xpath->query($sql)->item(0)->nodeValue;// 分析第2個/div/下的p下的相鄰span的第2個span的內容$sql = '//div/p/span[2]';echo $xpath->query($sql)->item(0)->nodeValue;PHP編程 鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。
新聞熱點





疑難解答