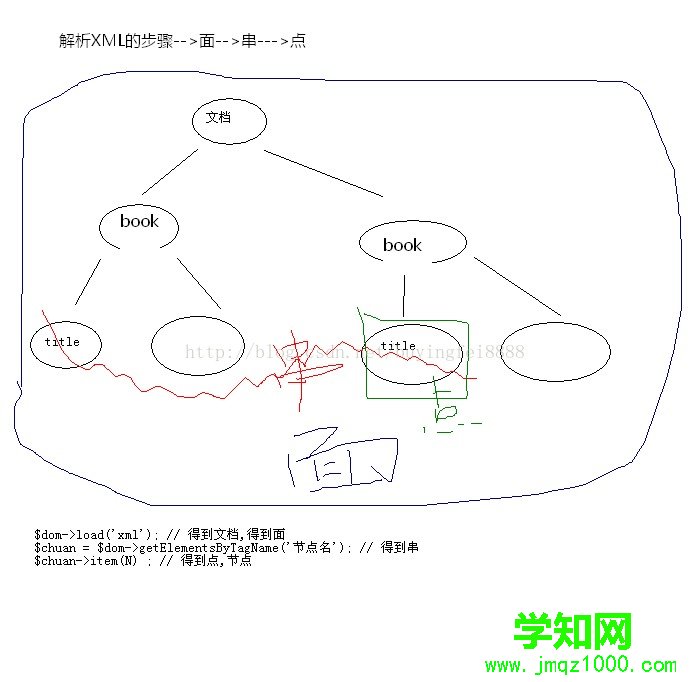
DOM解析XML和js類似,懂得js的話很隨意就讀取出相應值了。
DOM所有元素都是節點,這點不要忘啦!
大概是這樣:
XML文件:
<?xml version="1.0" encoding="utf-8"?><bookstore><book> <title>天龍八部</title> <price>28.8</price></book><book> <title>十八歌詩集</title> <price>29.9</price></book></bookstore>進行讀取:
<?php/***====筆記部分====XML的DOM解析document.getElementsByTagName();childNodes()這2個方法,是不是有點熟悉?答:是的,在js,java里也有為什么?答:因為XML是一種嚴格的文檔格式,有其自身的標準,解析XML,也有其標準,叫DOM標準,我們所使用的html,xml,都遵循DOM標準,也就是為什么我們看到上面的兩個函數那么熟悉.因為無論是PHP,java,c,js解析DOM樹,遵循的同樣的DOM標準.***//***如何通過php的DOM對象來解釋XML1:要把XML文件讀入進來,形成一個XML文檔對象 <--對應js--> document對象2:再通過getElementsByTagName('標簽名')得到一組節點<--js--> document.getElementsByTagName()3:再把2步中,得到一組對象,取得其某一個,就得到了具體的結點.***/// 1:創建DOM解析對象$dom = new DOMdocument('1.0','utf-8');/*DOMdocument Object有什么用?答:他可以把你的XML文件加載入內存并分析你就可以利用Object分析XML了*///print_r($dom); // DOMDocument Object ( ) //echo '<br />';// 2:載入XML文檔$dom->load('./01.xml'); // 得到文檔對象// 3:得到title節點列表/*分析,title節點有很多,因此得到的是"節點列表對象"*/$ts = $dom->getElementsByTagName('title');//print_r($ts); // DOMNodeList Object ( )/*DOMNodelist有1個屬性: length 代表取得的節點數量有1個方法: item(N) 代表取得第N個節點*//*echo '我們得到了',$ts->length,'個書名<br />';echo '第一個節點是'; print_r($ts->item(0));*/// "天龍八部"是一個文本節點,而且是<title></title>的子節點$title0 = $ts->item(0);print_r($title0->childNodes); // 打印結果 又是一個列表對象(子節點列表)echo $title0->childNodes->length,'個子節點<br />';$text = $title0->childNodes->item(0);print_r($text);echo $text->wholeText;echo '<hr />';echo $dom->getElementsByTagName('title')->item(1)->childNodes->item(0)->wholeText;echo '<hr />';echo $dom->getElementsByTagName('title')->item(1)->nodeValue;

還記得上次是用字符串截取獲得dom文檔,這次進行改正
<?php/***====筆記部分====目標:獲取土豆網的[無廣告]視頻地址一般的小偷程序:1:file_get_contents/curl -->頁面的html2:正則分析視頻地址缺點:1:慢,html頁面比較大,有大量的信息是"雜質"信息2:如果頁面改版了,采集規則可能失效.我們的采集辦法:利用土豆的API,得到XML信息1:XML是純數據,內容少,獲取快2:純數據,比如標題,時長等,這些是不會變的. 很難失效.目前,各大網站都有自己的開放接口, application programing interface,應用程序接口利用網站的API,就可查詢信息如豆瓣的書籍信息,土豆的視頻信息.....$key = 1f3918053ff6bc04***/error_reporting(E_ALL & ~E_NOTICE);if($tudou = $_POST['tudou']) { $itemcode = basename($tudou); $key = '1f3918053ff6bc04'; $api = 'http://api.tudou.com/v3/gw?method=item.info.get&appKey=' . $key . '&format=xml' . '&itemCodes=' . $itemcode; // echo $api; /* echo $api,得到的是一個XML文檔,內容是視頻的標題,時長,封面等等信息 接下來我們要做的是用PHP把XML的各節點信息解析出來 知識點: DOMDocument類來解析 當前,我們暫時不用XML解析 ,而是直接用字符串操作來得到地址 */ echo $api; $dom = new Domdocument('1.0','utf-8'); $dom->load($api); $noad = $dom->getElementsByTagName('html5Url')->item(0)->nodeValue;}?><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"><html xmlns="http://www.w3.org/1999/xhtml" lang="zh-CN"><head><title>新建網頁</title><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /><meta name="description" content="" /><meta name="keywords" content="" /><script type="text/javascript"></script><style type="text/css"></style></head> <body> <pre> 第28集http://www.tudou.com/programs/view/Dc6P2egJA4w/ </pre> <h3>這個地址需要支持html5的瀏覽器才能看,如chrome,火狐,IE9以上</h3> <form method="post"> <p> 土豆地址:<input type="text" name="tudou" /> </p> <p> <input type="submit" value="獲取地址" /> </p> </form> <p> 無廣告地址:<?php echo $noad; ?> </p> </body></html>PHP編程
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。
新聞熱點





疑難解答