Spark介紹
按照官方的定義,Spark 是一個通用,快速,適用于大規模數據的處理引擎。
通用性:我們可以使用Spark SQL來執行常規分析, Spark Streaming 來流數據處理, 以及用Mlib來執行機器學習等。Java,python,scala及R語言的支持也是其通用性的表現之一。
快速: 這個可能是Spark成功的最初原因之一,主要歸功于其基于內存的運算方式。當需要處理的數據需要反復迭代時,Spark可以直接在內存中暫存數據,而無需像Map Reduce一樣需要把數據寫回磁盤。官方的數據表明:它可以比傳統的Map Reduce快上100倍。
大規模:原生支持HDFS,并且其計算節點支持彈性擴展,利用大量廉價計算資源并發的特點來支持大規模數據處理。
環境準備
mongodb下載
解壓安裝
啟動mongodb服務
$MONGODB_HOME/bin/mongod --fork --dbpath=/root/data/mongodb/ --logpath=/root/data/log/mongodb/mongodb.log
pom依賴
<dependency> <groupId>org.mongodb.spark</groupId> <artifactId>mongo-spark-connector_2.11</artifactId> <version>${spark.version}</version> </dependency>實例代碼
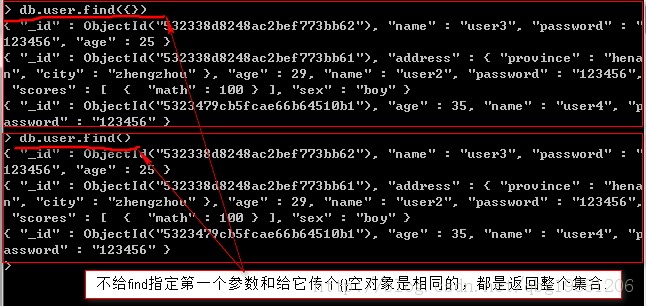
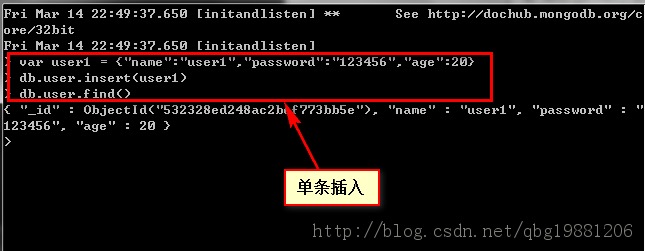
object ConnAppTest { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .master("local[2]") .appName("ConnAppTest") .config("spark.mongodb.input.uri", "mongodb://192.168.31.136/testDB.testCollection") // 指定mongodb輸入 .config("spark.mongodb.output.uri", "mongodb://192.168.31.136/testDB.testCollection") // 指定mongodb輸出 .getOrCreate() // 生成測試數據 val documents = spark.sparkContext.parallelize((1 to 10).map(i => Document.parse(s"{test: $i}"))) // 存儲數據到mongodb MongoSpark.save(documents) // 加載數據 val rdd = MongoSpark.load(spark) // 打印輸出 rdd.show } }總結
以上所述是小編給大家介紹的Spark整合Mongodb的方法,希望對大家有所幫助,如果大家有任何疑問請給我留言,小編會及時回復大家的。在此也非常感謝大家對武林網網站的支持!
新聞熱點




疑難解答