在以上兩篇文章中已經(jīng)介紹到了 Python 爬蟲和 MongoDB , 那么下面我就將爬蟲爬下來的數(shù)據(jù)存到 MongoDB 中去,首先來介紹一下我們將要爬取的網(wǎng)站, readfree 網(wǎng)站,這個網(wǎng)站非常的好,我們只需要每天簽到就可以免費下載三本書,良心網(wǎng)站,下面我就將該網(wǎng)站上的每日推薦書籍爬下來。

利用上面幾篇文章介紹的方法,我們很容易的就可以在網(wǎng)頁的源代碼中尋找到書籍的姓名和書籍作者的信息。
找到之后我們復制 XPath ,然后進行提取即可。源代碼如下所示
# coding=utf-8import reimport requestsfrom lxml import etreeimport pymongoimport sysreload(sys)sys.setdefaultencoding('utf-8')def getpages(url, total): nowpage = int(re.search('(/d+)', url, re.S).group(1)) urls = [] for i in range(nowpage, total + 1): link = re.sub('(/d+)', '%s' % i, url, re.S) urls.append(link) return urlsdef spider(url): html = requests.get(url) selector = etree.HTML(html.text) book_name = selector.xpath('//*[@id="container"]/ul/li//div/div[2]/a/text()') book_author = selector.xpath('//*[@id="container"]/ul/li//div/div[2]/div/a/text()') saveinfo(book_name, book_author)def saveinfo(book_name, book_author): connection = pymongo.MongoClient() BookDB = connection.BookDB BookTable = BookDB.books length = len(book_name) for i in range(0, length): books = {} books['name'] = str(book_name[i]).replace('/n','') books['author'] = str(book_author[i]).replace('/n','') BookTable.insert_one(books)if __name__ == '__main__': url = 'http://readfree.me/shuffle/?page=1' urls = getpages(url,3) for each in urls: spider(each)注意,在寫入數(shù)據(jù)庫的過程中不要一下子將字典中的數(shù)據(jù)寫入數(shù)據(jù)庫,我一開始就這么寫的,但是我發(fā)現(xiàn)數(shù)據(jù)庫中只有三條信息,其他信息都不見了。所以采用一條一條的寫入。
還有源代碼的開頭部分,對默認編碼的設置一定不可以省略,否則可能會報編碼錯誤(真心感覺 Python 在編碼這方面好容易出錯,尷尬)。
有的人可能發(fā)現(xiàn)了,我將提取的信息轉換成了字符串,然后使用 replace() 方法將 /n 去掉了,因為我發(fā)現(xiàn)在提取的書籍信息前后存在換行符,看著十分礙眼。
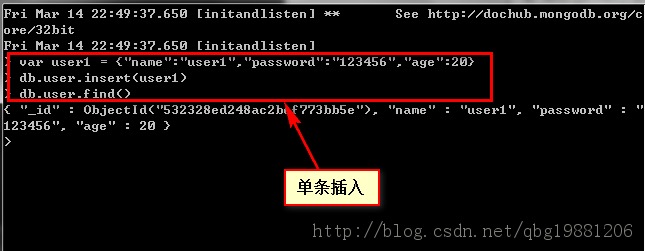
熱情提醒一下,在程序運行的時候別忘記將你的 Mongo DB 運行起來,下來看看結果

好了,就這樣,如果發(fā)現(xiàn)代碼哪里存在錯誤或者說有可以改善的地方,希望留言給我,感謝。
新聞熱點




疑難解答