作為一個網頁設計者, 你創建客戶端的 CGI腳本, 服務器端的程序用來處理用戶輸入, 結果返回給用戶.
在這里你將學習關于CGI腳本的一切:
CGI 腳本難道不是一個真正的腳本?按照你的服務器的支持, 他們可能是一個編譯好的程序或者批命令文件或者其他可執行的東西. 為了簡單起見,我們統稱他們為腳本scripts.
CGI腳本是用下列兩種方法使用的: 作為一個表單的ACTION 或 作為一個頁中的直接link。
圖1. 從瀏覽器到服務器到腳本到程序 記住再回來噢!
這有個簡短的示意解釋:
Display Date處是個指向CGI腳本的連接. 它的HTML是這樣的:
<A >Display the Date</A>說明是個CGI腳本是因為這里面有個cgi-bin的路徑. 在許多服務器cgi-bin是僅能夠放置CGI腳本的目錄.
當你選擇這個連接時, 你的瀏覽器將向www.popchina.com服務器提出請求. 服務器接收這個請求計算出URL處的腳本文件名然后執行這個腳本.
這個getdate腳本, 在UNIX系統中執行是這樣的:
#!/bin/shecho Content-type: text/plainecho/bin/date第一行是個特殊的命令,告訴UNIX系統這是個shell腳本; 真實的情況是從這行開始的下一行,這個腳本做兩件事:它輸出行Content-type: text/plain, 接著開始一個空行;第二, 它調用UNIX系統時間date程序, 這樣輸出日期和時間. 腳本執行后輸出應該這樣:
Content-type: text/plainTue Oct 25 16:15:57 EDT 1994這個Content-type是什么東東?它是個特殊的編碼,Web服務器用來告訴瀏覽器輸出這個文本是什么類型的. 這與HTML中Content-type含義是一樣的。
這樣瀏覽器的輸出就如圖3.
圖3 date腳本輸出結果.
這是最基本的,實際情況要復雜得多,總之可以用來理解瀏覽器、服務器和腳本之間是怎樣工作的。
肯定嗎?就是做不到,學學也可以?好吧!讓我們繼續.
但是即使你有一個Web服務器, 這個服務器必須特別地為運行CGI腳本配置一下. 那意味著你所有的腳本必須放置在一個叫做cgi-bin的目錄下.
在編寫CGI腳本之前, 詢問你的服務器管理者是否允許你安裝和運行CGI腳本, 并且如果可以的話,他們必須放置在哪兒?還有,你必須有個真正的Web服務器,如果是FTP或Gopher服務器,那你就不能用CGI.
如果你在自己的服務器上運行, 你必須特別地創造一個叫cgi-bin的目錄,并配置你的服務器認可這個目錄為一個腳本目錄. 也必須記住下面有關CGI腳本特點:
在這本學習手冊中,僅用兩種語言編寫CGI腳本: UNIX shell和 Perl語言. 這個shell是適合在任何相近的UNIX系統上運行并且容易學習, 但是處理復雜的情況就困難了. Perl, 就要用這個語言了, 它是免費的, 這個語言是穩定和強大的,類似C,但它也是較難學習的.
如果你是租用服務器,就要是否允許運行CGI腳本.
如果你擁有自己的服務器,檢查你的服務器說明書是怎樣處理CGI腳本的.
這個頭部是實際不是文本的一部分,是服務器與瀏覽器之間的信息協議,你實際看不到。
有三個類型的頭部: Content-type, Location, 和Status. Content-type 最普遍的。
有關content-type解釋可以見有關HTML的說明, 一個你可以發出的特定編碼象這樣:
Content-type: text/html在這個例子中,輸出數據的類型是text/html; 換句話說, 他是個HTML文件.
Format | Content-Type |
| HTML | text/html |
| Text | text/plain |
| GIF | image/gif |
| JPEG | image/jpeg |
| PostScript | application/postscript |
| MPEG | video/mpeg |
圖4. 腳本的結果
這是個很簡單的例子, 他能這樣備調用:
<A >Is Laura Logged in?</A>這是沒有輸入的腳本,它只運行并且返回數據.
根據前面的闡述,這個腳本內容是這樣::
#!/bin/sh
echo Content-type: text/html
echo "<HTML><HEAD>"
echo "<TITLE>Is Laura There?</TITLE>"
echo "</HEAD><BODY>"
為了測試我是否已經登陸系統,用who命令(我的登陸名假設為lemay), 儲存結果在變量ison中. 如果我登陸, 變量ison將有些內容,否則則是空的.
ison='who | grep lemay'試驗結果及返回相應提示的腳本是這樣:
if [ ! -z "$ison" ]; then echo "<P>Laura is logged in."</P>else echo "<P>Laura isn't logged in."</P>fi最后關閉HTML:
echo "</BODY></HTML>"現在你通過從命令行運行他,測試一下,你將得到一個結果說我未登陸你的系統,當然不可能的,他的輸出是這樣的:
Content-type: text/html<HTML><HEAD><TITLE>Are You There?</TITLE></HEAD><BODY><P>Laura is not logged in.</BODY></HTML>這是輸出的一個HTML文本,這樣你的瀏覽器能正常顯示他,因為他是個HTML文件。
這個例子完整的腳本如下:
#!/bin/shecho "Content-type: text/html"echoecho "<HTML><HEAD>"echo "<TITLE>Is Laura There?</TITLE>"echo "</HEAD><BODY>"ison='who | grep lemay'if [ ! -z "$ison" ]; then echo "<P>Laura is logged in"else echo "<P>Laura isn't logged in"fiecho "</BODY></HTML>"
<A HREF="/cgi-bin/myscript?arg1+arg2+arg3">run my script</A>當服務器接收到這個請求,它傳遞 arg1, arg2, 和 arg3 參數給腳本. 你然后能在腳本中使用這些參數.
這個方法有時叫查詢, 因為早期它用在搜索功能中.
我們取個不同題目:
#!/bin/shecho "Content-type: text/html"echoecho "<HTML><HEAD>"echo "<TITLE>Are You There?</TITLE>"echo "</HEAD><BODY>"在上面的例子中, 下一步應該是測試我是否登陸,在這里我們用參數${1}代替我的名字lemay, ${1}作為第一個參數, ${2}作為第二個, ${3}作為第三個.
ison='who | grep "${1}"'剩下的所有修改如下:
if [ ! -z "$ison" ]; then echo "<P>$1 is logged in"else echo "<P>$1 isn't logged in"fi
echo "</BODY></HTML>"好了,讓我們修改HTML頁中的連接吧!原來是這樣:
<A >Is Laura Logged in?</A>修改為通用查詢功能后是這樣,比如查詢名字叫john的人是否登陸:
<A >Is John Logged in?</A>在你的服務器上試試,看是否有結果。
看下面一個路徑信息path information例子, :
http://myhost/cgi-bin/myscript/remaining_path_info?arg1+arg2當腳本運行時,在路徑中的信息將被放置于環境參數PATH_INFO. 你能在你的腳本內容中使用這些信息.
比如說, 讓我們假設你在多頁上已有多個連接到同一個腳本. 你能用這個路徑信息顯示那個有連接的HTML文件名. 這樣, 在你完成處理你的腳本之后, 當你發回一個HTML文件時, 你能在這個文件里包含一個連接,發回用戶一開始那個頁。
你會在下一章節學到更多路徑信息:有用的表單和腳本. 待后來登出
不用怕, 這里開始解釋這些情況.
Location: ../docs/final.html這個Location行用作通常的輸出位置,也就是說,如果你用了Location, 你就不必再用象Content-type這樣的數據輸出(實際上,你也不能). 正如Content-type, 你也必須在這一行后面跟一個空行.
指向這個文件的路徑可以是一個URL或相對路徑. 所有相對路徑是指相對于腳本所在的位置. 例子中的final.html文本是在當前上一個目錄下docs的目錄下:
echo Location: ../docs/final.htmlecho
很幸運, 這一切很容易. 你只要輸出下面這個命令即可(后面跟一個空行):
echo Status: 204 No Responseecho這個Status頭部提供狀態碼給服務器(并且也給瀏覽器). 特別的204將傳遞給瀏覽器,如果能識別它,它將什么也不做.
記住, 大多數表單有兩個部分: HTML的表單格式;處理表單數據的CGI腳本. 這個CGI腳本使用標簽<FORM>屬性調用的.
這個ACTION屬性包含著處理表單的腳本:
<FORM ACTION="http://www.popchina.com/cgi-bin/processorscript">在這個表單中, 每個輸入區都有一個NAME的屬性, 用來稱呼表單元素. 當這個表單數據被遞交給你在ACTION中定義的CGI腳本, 這樣這些name和輸入內容被作為一個數字或字符傳遞給腳本.
我們上面談論的方法,實際是GET,它將數據打包放置在環境變量QUERY_STRING中作為URL整體的一部分傳遞給服務器。
POST做很多類似GET同樣的事情, 不同的地方就是它是分離地傳遞數據給腳本. 你的腳本通過標準輸入獲取這些數據. (有些Web服務器是存儲在臨時文件中.) 這個QUERY_STRING環境變量將不再設置.
那你用那個方法呢? POST是個安全的方法, 尤其如果你的表單中有很多數據的話. 當你用GET, 這個服務器就分配變量QUERY_STRING給所有的表單數據, 但是這個變量可存儲量是有限的. 換句話說,如果你有很多數據但是你又用GET,你會丟失很多數據.
如果你用POST, 你可以盡可能多地使用數據, 因為這些數據從來也不分配到一個變量里.
theName=Ichabod+Crane&gender=male&status=missing&headless=yesURL編碼遵循下列規則:
這里介紹一個叫uncgi的解碼程序, 你可以從http://www.hyperion.com/~koreth/uncgi.html. 得到原碼,安裝在你自己的cgi-bin目錄下.
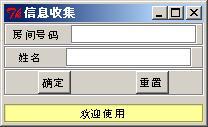
圖5. 告訴我你的名字的表單.
這個輸入被發給腳本, 然后發回顯示一個hello的信息(間圖.6).
如果你在姓名輸入處不輸入任何東東,會怎樣?見圖7.
圖6. 姓名表單的結果.
圖7. 另一個結果.
<FORM METHOD=POST ACTION="../cgi-bin/form-name"></FORM>如果你在用uncgi從input中解碼, 情況有點不同. 為了是uncgi正常工作, 你首先必須調用uncgi , 如果uncgi是個目錄,加上實際的腳本名, 象這樣:
<FORM METHOD=POST ACTION="../cgi-bin/uncgi/form-name"></FORM>這樣,你不必修改表單中原始的HTML; 原始的HTML可以工作得很好.
在腳本中第一步是解碼,在這個例子中, 我們已經使用uncgi解碼輸入數據, 實際這個表單已經為你做好解碼. 通過建立一個uncgi的目錄,一旦表單遞交給服務器,服務器會自動進行解碼,這樣,所有的name/value已經準備就緒等待你的使用.
現在,一個例子開始部分假設是下面這樣:
echo Content-type: text/htmlechoecho "<HTML><HEAD>"echo "<TITLE>Hello</TITLE>"echo "</HEAD><BODY>"echo "<P>"接下來,有兩種情況要處理:一件是處理用戶不輸入名字的情況,一個是如果輸入了向他們說hello.
這個Name元素的值, 是包含在WWW_theName環境變量中. 用一個簡單的測試命令(-z), 你能查看環境變量是否是空的還是包括相應的輸出值:
if [ ! -z "$WWW_theName" ]; then echo "Hello, " echo $WWW_theNameelse echo "You don't have a name?"fi最后增加一個連接"go back" . 用來返回:
echo "</P><P><A HREF="../lemay/name1.html">Go Back</A></P>"echo "</BODY></HTML>"
你正確配置了你的服務器運行CGI腳本? 你的腳本是放置在cgi-bin目錄中嗎?如果你的服務器允許帶.cgi擴展名的CGI運行, 你的腳本文件名的擴展名是這樣嗎?
解答還是如上一條一樣,然后你用命令行執行你的CGI,可以正常運行嗎?是否有錯誤?.
確定你的頭部行和數據部之間有一空行.
確定你的腳本是可執行的(在UNIX, 用chmod +x 你的腳本.cgi). 在從瀏覽器運行之前,你應當從命令行運行你的腳本,如果客戶端是win95,可以用telnet登陸你的服務器,執行命令行,當然必須了解UNIX命令.
環境變量 | 意義 |
| SERVER_NAME | CGI腳本運行時的主機名和IP地址. |
| SERVER_SOFTWARE | 你的服務器的類型如: CERN/3.0 或 NCSA/1.3. |
| GATEWAY_INTERFACE | 運行的CGI版本. 對于UNIX服務器, 這是CGI/1.1. |
| SERVER_PROTOCOL | 服務器運行的HTTP協議. 這里當是HTTP/1.0. |
| SERVER_PORT | 服務器運行的TCP口,通常Web服務器是80. |
| REQUEST_METHOD | POST 或 GET, 取決于你的表單是怎樣遞交的. |
| HTTP_ACCEPT | 瀏覽器能直接接收的Content-types, 可以有HTTP Accept header定義. |
| HTTP_USER_AGENT | 遞交表單的瀏覽器的名稱、版本 和其他平臺性的附加信息。 |
| HTTP_REFERER | 遞交表單的文本的 URL,不是所有的瀏覽器都發出這個信息,不要依賴它 |
| PATH_INFO | 附加的路徑信息, 由瀏覽器通過GET方法發出. |
| PATH_TRANSLATED | 在PATH_INFO中系統規定的路徑信息. |
| SCRIPT_NAME | 指向這個CGI腳本的路徑, 是在URL中顯示的(如, /cgi-bin/thescript). |
| QUERY_STRING | 腳本參數或者表單輸入項(如果是用GET遞交). QUERY_STRING 包含URL中問號后面的參數. |
| REMOTE_HOST | 遞交腳本的主機名,這個值不能被設置. |
| REMOTE_ADDR | 遞交腳本的主機IP地址. |
| REMOTE_USER | 遞交腳本的用戶名. 如果服務器的authentication被激活,這個值可以設置。 |
| REMOTE_IDENT | 如果Web服務器是在ident (一種確認用戶連接你的協議)運行, 遞交表單的系統也在運行ident, 這個變量就含有ident返回值. |
| CONTENT_TYPE | 如果表單是用POST遞交, 這個值將是 application/x-www-form-urlencoded. 在上載文件的表單中, content-type 是個 multipart/form-data. |
| CONTENT_LENGTH | 對于用POST遞交的表單, 標準輸入口的字節數. |
當然也有表單上載時可以解碼的程序,很少。
為了使用cgi-lib.pl,你通常要這樣寫:
#!/usr/lib/perl
require 'cgi-lib.pl';cgi-lib中盡管有很多子程序, 最重要的是ReadParse子程. ReadParse 讀取輸入方便地將name/value儲存在一個Perl陣列中. 在你的Perl腳本中通常是這樣調用的:
&ReadParse(*in);此例中,陣列名是in, 可以隨便取名的.
在表單輸入解碼后, 你能讀取和處理這個name/value,方法是象下面這樣:
print $in{'theName'};這個將顯示名字name是theName的值value. 如果你有多個用同樣名字的name對, cgi-lib.pl用(/0)分隔多個名字. 這樣可以正常處理你的腳本.
cgi-lib.pl 后來版本可以很好支持, 在http://www.bio.cam.ac.uk/cgi-lib/ 了解更多的情況.
另一個處理用Perl編寫的CGI地址是 http://valine.ncsa.uiuc.edu/cgi_docs.html .
注意:上述程序可以用ultra edit來編輯,注意轉換UNIX格式 ,必須采用UNIX格式存盤,再上載,用telnet登陸,在命令行鍵入perl sample.pl,看有無bug,再 在瀏覽器中調用。CGI程序包括放置CGI的目錄一定要改屬性為777, 要寫入的HTML文件也要改屬性為777.
現在網上有很多免費的cgi,基本可以滿足一般需求,請到這個網址查詢你要的cgi:http://www.itm.com/cgicollection/
本人漢化了一個古老的通用留言簿,大家可以拿去做自己的留言簿。這里下載
新聞熱點




疑難解答