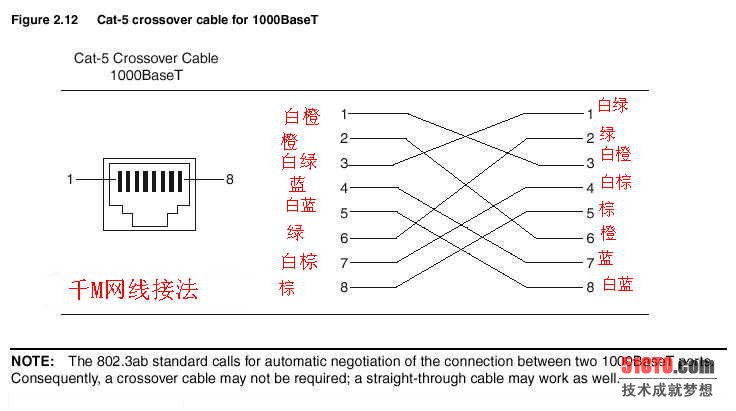
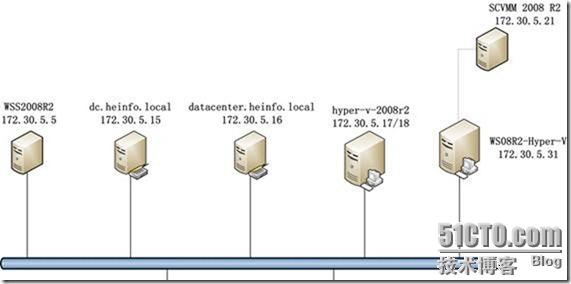
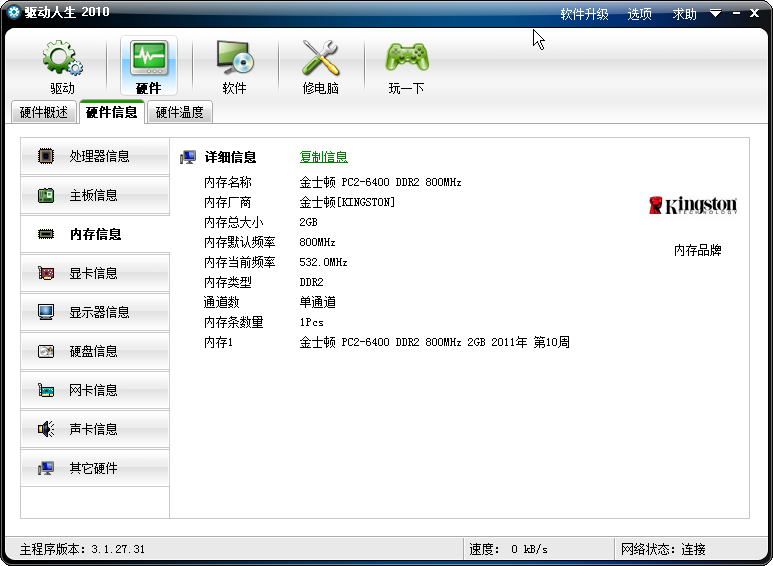
如果當SQL數據庫中select語句數目過多,就會影響數據庫的性能,如果需要查詢n個Customer對象,那么必須執行n+1次select查詢語句,下文就將為您講解這個n+1次select查詢問題。
在session的緩存中存放的是相互關聯的對象圖。默認情況下,當hibernate從數據庫中加載Customer對象時,會同時加載所有關聯的Order對象。以Customer和Order類為例,假定ORDERS表的CUSTOMER_ID外鍵允許為null,圖1列出了CUSTOMERS表和ORDERS表中的記錄。
以下Session的find()方法用于到數據庫中檢索所有的Customer對象:List customerLists=session.find("from Customer as c");運行以上find()方法時,Hibernate將先查詢CUSTOMERS表中所有的記錄,然后根據每條記錄的ID,到ORDERS表中查詢有參照關系的記錄,Hibernate將依次執行以下select語句:select * from CUSTOMERS; select * from ORDERS where CUSTOMER_ID=1;select * from ORDERS where CUSTOMER_ID=2;select * from ORDERS where CUSTOMER_ID=3;select * from ORDERS where CUSTOMER_ID=4;通過以上5條select語句,Hibernate最后加載了4個Customer對象和5個Order對象,在內存中形成了一幅關聯的對象圖,參見圖2。
 Hibernate在檢索與Customer關聯的Order對象時,使用了默認的立即檢索策略。這種檢索策略存在兩大不足:(1) select語句的數目太多,需要頻繁的訪問數據庫,會影響檢索性能。如果需要查詢n個Customer對象,那么必須執行n+1次select查詢語句。這就是經典的n+1次select查詢問題。這種檢索策略沒有利用SQL的連接查詢功能,例如以上5條select語句完全可以通過以下1條select語句來完成:select * from CUSTOMERS left outer join ORDERS on CUSTOMERS.ID=ORDERS.CUSTOMER_ID 以上select語句使用了SQL的左外連接查詢功能,能夠在一條select語句中查詢出CUSTOMERS表的所有記錄,以及匹配的ORDERS表的記錄。(2)在應用邏輯只需要訪問Customer對象,而不需要訪問Order對象的場合,加載Order對象完全是多余的操作,這些多余的Order對象白白浪費了許多內存空間。為了解決以上問題,Hibernate提供了其他兩種檢索策略:延遲檢索策略和迫切左外連接檢索策略。延遲檢索策略能避免多余加載應用程序不需要訪問的關聯對象,迫切左外連接檢索策略則充分利用了SQL的外連接查詢功能,能夠減少select語句的數目。
Hibernate在檢索與Customer關聯的Order對象時,使用了默認的立即檢索策略。這種檢索策略存在兩大不足:(1) select語句的數目太多,需要頻繁的訪問數據庫,會影響檢索性能。如果需要查詢n個Customer對象,那么必須執行n+1次select查詢語句。這就是經典的n+1次select查詢問題。這種檢索策略沒有利用SQL的連接查詢功能,例如以上5條select語句完全可以通過以下1條select語句來完成:select * from CUSTOMERS left outer join ORDERS on CUSTOMERS.ID=ORDERS.CUSTOMER_ID 以上select語句使用了SQL的左外連接查詢功能,能夠在一條select語句中查詢出CUSTOMERS表的所有記錄,以及匹配的ORDERS表的記錄。(2)在應用邏輯只需要訪問Customer對象,而不需要訪問Order對象的場合,加載Order對象完全是多余的操作,這些多余的Order對象白白浪費了許多內存空間。為了解決以上問題,Hibernate提供了其他兩種檢索策略:延遲檢索策略和迫切左外連接檢索策略。延遲檢索策略能避免多余加載應用程序不需要訪問的關聯對象,迫切左外連接檢索策略則充分利用了SQL的外連接查詢功能,能夠減少select語句的數目。
http://blog.csdn.net/z69183787/article/details/46288815
新聞熱點






疑難解答