一、前置知識(shí)詳解
Spark SQL重要是操作DataFrame,DataFrame本身提供了save和load的操作,
Load:可以創(chuàng)建DataFrame,
Save:把DataFrame中的數(shù)據(jù)保存到文件或者說(shuō)與具體的格式來(lái)指明我們要讀取的文件的類型以及與具體的格式來(lái)指出我們要輸出的文件是什么類型。
二、Spark SQL讀寫數(shù)據(jù)代碼實(shí)戰(zhàn)
import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.Function;import org.apache.spark.sql.*;import org.apache.spark.sql.types.DataTypes;import org.apache.spark.sql.types.StructField;import org.apache.spark.sql.types.StructType;import java.util.ArrayList;import java.util.List;public class SparkSQLLoadSaveOps { public static void main(String[] args) { SparkConf conf = new SparkConf().setMaster("local").setAppName("SparkSQLLoadSaveOps"); JavaSparkContext sc = new JavaSparkContext(conf); SQLContext = new SQLContext(sc); /** * read()是DataFrameReader類型,load可以將數(shù)據(jù)讀取出來(lái) */ DataFrame peopleDF = sqlContext.read().format("json").load("E://Spark//Sparkinstanll_package//Big_Data_Software//spark-1.6.0-bin-hadoop2.6//examples//src//main//resources//people.json"); /** * 直接對(duì)DataFrame進(jìn)行操作 * Json: 是一種自解釋的格式,讀取Json的時(shí)候怎么判斷其是什么格式? * 通過(guò)掃描整個(gè)Json。掃描之后才會(huì)知道元數(shù)據(jù) */ //通過(guò)mode來(lái)指定輸出文件的是append。創(chuàng)建新文件來(lái)追加文件 peopleDF.select("name").write().mode(SaveMode.Append).save("E://personNames"); }} 讀取過(guò)程源碼分析如下:
1. read方法返回DataFrameReader,用于讀取數(shù)據(jù)。
/** * :: Experimental :: * Returns a [[DataFrameReader]] that can be used to read data in as a [[DataFrame]]. * {{{ * sqlContext.read.parquet("/path/to/file.parquet") * sqlContext.read.schema(schema).json("/path/to/file.json") * }}} * * @group genericdata * @since 1.4.0 */@Experimental//創(chuàng)建DataFrameReader實(shí)例,獲得了DataFrameReader引用def read: DataFrameReader = new DataFrameReader(this)2. 然后再調(diào)用DataFrameReader類中的format,指出讀取文件的格式。
/** * Specifies the input data source format. * * @since 1.4.0 */def format(source: String): DataFrameReader = { this.source = source this}3. 通過(guò)DtaFrameReader中l(wèi)oad方法通過(guò)路徑把傳入過(guò)來(lái)的輸入變成DataFrame。
/** * Loads input in as a [[DataFrame]], for data sources that require a path (e.g. data backed by * a local or distributed file system). * * @since 1.4.0 */// TODO: Remove this one in Spark 2.0.def load(path: String): DataFrame = { option("path", path).load()} 至此,數(shù)據(jù)的讀取工作就完成了,下面就對(duì)DataFrame進(jìn)行操作。
下面就是寫操作!!!
1. 調(diào)用DataFrame中select函數(shù)進(jìn)行對(duì)列篩選
/** * Selects a set of columns. This is a variant of `select` that can only select * existing columns using column names (i.e. cannot construct expressions). * * {{{ * // The following two are equivalent: * df.select("colA", "colB") * df.select($"colA", $"colB") * }}} * @group dfops * @since 1.3.0 */@scala.annotation.varargsdef select(col: String, cols: String*): DataFrame = select((col +: cols).map(Column(_)) : _*)2. 然后通過(guò)write將結(jié)果寫入到外部存儲(chǔ)系統(tǒng)中。
/** * :: Experimental :: * Interface for saving the content of the [[DataFrame]] out into external storage. * * @group output * @since 1.4.0 */@Experimentaldef write: DataFrameWriter = new DataFrameWriter(this)
3. 在保持文件的時(shí)候mode指定追加文件的方式
/** * Specifies the behavior when data or table already exists. Options include:// Overwrite是覆蓋 * - `SaveMode.Overwrite`: overwrite the existing data.//創(chuàng)建新的文件,然后追加 * - `SaveMode.Append`: append the data. * - `SaveMode.Ignore`: ignore the operation (i.e. no-op). * - `SaveMode.ErrorIfExists`: default option, throw an exception at runtime. * * @since 1.4.0 */def mode(saveMode: SaveMode): DataFrameWriter = { this.mode = saveMode this}4. 最后,save()方法觸發(fā)action,將文件輸出到指定文件中。
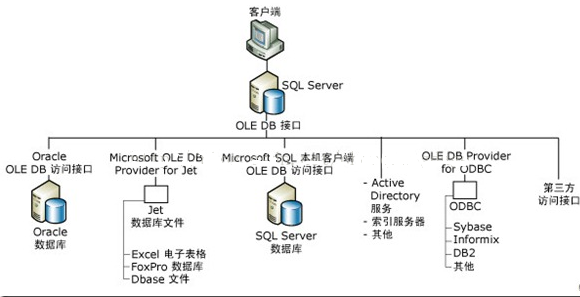
/** * Saves the content of the [[DataFrame]] at the specified path. * * @since 1.4.0 */def save(path: String): Unit = { this.extraOptions += ("path" -> path) save()}三、Spark SQL讀寫整個(gè)流程圖如下
據(jù)加載和保存實(shí)例講解")
四、對(duì)于流程中部分函數(shù)源碼詳解
DataFrameReader.Load()
1. Load()返回DataFrame類型的數(shù)據(jù)集合,使用的數(shù)據(jù)是從默認(rèn)的路徑讀取。
/** * Returns the dataset stored at path as a DataFrame, * using the default data source configured by spark.sql.sources.default. * * @group genericdata * @deprecated As of 1.4.0, replaced by `read().load(path)`. This will be removed in Spark 2.0. */@deprecated("Use read.load(path). This will be removed in Spark 2.0.", "1.4.0")def load(path: String): DataFrame = {//此時(shí)的read就是DataFrameReader read.load(path)} 2. 追蹤load源碼進(jìn)去,源碼如下:
在DataFrameReader中的方法。Load()通過(guò)路徑把輸入傳進(jìn)來(lái)變成一個(gè)DataFrame。
/** * Loads input in as a [[DataFrame]], for data sources that require a path (e.g. data backed by * a local or distributed file system). * * @since 1.4.0 */// TODO: Remove this one in Spark 2.0.def load(path: String): DataFrame = { option("path", path).load()}3. 追蹤load源碼如下:
/** * Loads input in as a [[DataFrame]], for data sources that don't require a path (e.g. external * key-value stores). * * @since 1.4.0 */def load(): DataFrame = {//對(duì)傳入的Source進(jìn)行解析 val resolved = ResolvedDataSource( sqlContext, userSpecifiedSchema = userSpecifiedSchema, partitionColumns = Array.empty[String], provider = source, options = extraOptions.toMap) DataFrame(sqlContext, LogicalRelation(resolved.relation))}DataFrameReader.format()
1. Format:具體指定文件格式,這就獲得一個(gè)巨大的啟示是:如果是Json文件格式可以保持為Parquet等此類操作。
Spark SQL在讀取文件的時(shí)候可以指定讀取文件的類型。例如,Json,Parquet.
/** * Specifies the input data source format.Built-in options include “parquet”,”json”,etc. * * @since 1.4.0 */def format(source: String): DataFrameReader = { this.source = source //FileType this}DataFrame.write()
1. 創(chuàng)建DataFrameWriter實(shí)例
/** * :: Experimental :: * Interface for saving the content of the [[DataFrame]] out into external storage. * * @group output * @since 1.4.0 */@Experimentaldef write: DataFrameWriter = new DataFrameWriter(this)1
2. 追蹤DataFrameWriter源碼如下:
以DataFrame的方式向外部存儲(chǔ)系統(tǒng)中寫入數(shù)據(jù)。
/** * :: Experimental :: * Interface used to write a [[DataFrame]] to external storage systems (e.g. file systems, * key-value stores, etc). Use [[DataFrame.write]] to access this. * * @since 1.4.0 */@Experimentalfinal class DataFrameWriter private[sql](df: DataFrame) {DataFrameWriter.mode()
1. Overwrite是覆蓋,之前寫的數(shù)據(jù)全都被覆蓋了。
Append:是追加,對(duì)于普通文件是在一個(gè)文件中進(jìn)行追加,但是對(duì)于parquet格式的文件則創(chuàng)建新的文件進(jìn)行追加。
/** * Specifies the behavior when data or table already exists. Options include: * - `SaveMode.Overwrite`: overwrite the existing data. * - `SaveMode.Append`: append the data. * - `SaveMode.Ignore`: ignore the operation (i.e. no-op).//默認(rèn)操作 * - `SaveMode.ErrorIfExists`: default option, throw an exception at runtime. * * @since 1.4.0 */def mode(saveMode: SaveMode): DataFrameWriter = { this.mode = saveMode this}2. 通過(guò)模式匹配接收外部參數(shù)
/** * Specifies the behavior when data or table already exists. Options include: * - `overwrite`: overwrite the existing data. * - `append`: append the data. * - `ignore`: ignore the operation (i.e. no-op). * - `error`: default option, throw an exception at runtime. * * @since 1.4.0 */def mode(saveMode: String): DataFrameWriter = { this.mode = saveMode.toLowerCase match { case "overwrite" => SaveMode.Overwrite case "append" => SaveMode.Append case "ignore" => SaveMode.Ignore case "error" | "default" => SaveMode.ErrorIfExists case _ => throw new IllegalArgumentException(s"Unknown save mode: $saveMode. " + "Accepted modes are 'overwrite', 'append', 'ignore', 'error'.") } this}DataFrameWriter.save()
1. save將結(jié)果保存?zhèn)魅氲穆窂健?/p>
/** * Saves the content of the [[DataFrame]] at the specified path. * * @since 1.4.0 */def save(path: String): Unit = { this.extraOptions += ("path" -> path) save()}2. 追蹤save方法。
/** * Saves the content of the [[DataFrame]] as the specified table. * * @since 1.4.0 */def save(): Unit = { ResolvedDataSource( df.sqlContext, source, partitioningColumns.map(_.toArray).getOrElse(Array.empty[String]), mode, extraOptions.toMap, df)} 3. 其中source是SQLConf的defaultDataSourceName
private var source: String = df.sqlContext.conf.defaultDataSourceName
其中DEFAULT_DATA_SOURCE_NAME默認(rèn)參數(shù)是parquet。
// This is used to set the default data sourceval DEFAULT_DATA_SOURCE_NAME = stringConf("spark.sql.sources.default", defaultValue = Some("org.apache.spark.sql.parquet"), doc = "The default data source to use in input/output.")DataFrame.scala中部分函數(shù)詳解:
1. toDF函數(shù)是將RDD轉(zhuǎn)換成DataFrame
/** * Returns the object itself. * @group basic * @since 1.3.0 */// This is declared with parentheses to prevent the Scala compiler from treating// `rdd.toDF("1")` as invoking this toDF and then apply on the returned DataFrame.def toDF(): DataFrame = this2. show()方法:將結(jié)果顯示出來(lái)
/** * Displays the [[DataFrame]] in a tabular form. For example: * {{{ * year month AVG('Adj Close) MAX('Adj Close) * 1980 12 0.503218 0.595103 * 1981 01 0.523289 0.570307 * 1982 02 0.436504 0.475256 * 1983 03 0.410516 0.442194 * 1984 04 0.450090 0.483521 * }}} * @param numRows Number of rows to show * @param truncate Whether truncate long strings. If true, strings more than 20 characters will * be truncated and all cells will be aligned right * * @group action * @since 1.5.0 */// scalastyle:off printlndef show(numRows: Int, truncate: Boolean): Unit = println(showString(numRows, truncate))// scalastyle:on println追蹤showString源碼如下:showString中觸發(fā)action收集數(shù)據(jù)。
/** * Compose the string representing rows for output * @param _numRows Number of rows to show * @param truncate Whether truncate long strings and align cells right */private[sql] def showString(_numRows: Int, truncate: Boolean = true): String = { val numRows = _numRows.max(0) val sb = new StringBuilder val takeResult = take(numRows + 1) val hasMoreData = takeResult.length > numRows val data = takeResult.take(numRows) val numCols = schema.fieldNames.length以上就是本文的全部?jī)?nèi)容,希望對(duì)大家的學(xué)習(xí)有所幫助,也希望大家多多支持VeVb武林網(wǎng)。
新聞熱點(diǎn)






疑難解答
圖片精選