制作一個(gè)爬蟲一般分以下幾個(gè)步驟:
分析需求分析網(wǎng)頁源代碼,配合開發(fā)者工具編寫正則表達(dá)式或者XPath表達(dá)式正式編寫 python 爬蟲代碼 效果預(yù)覽
運(yùn)行效果如下:
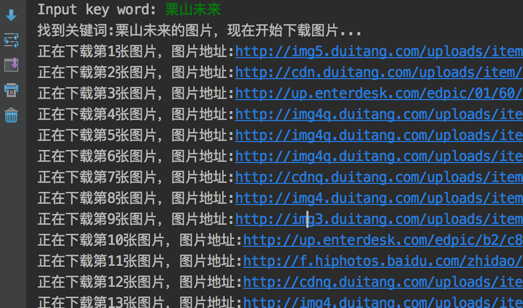
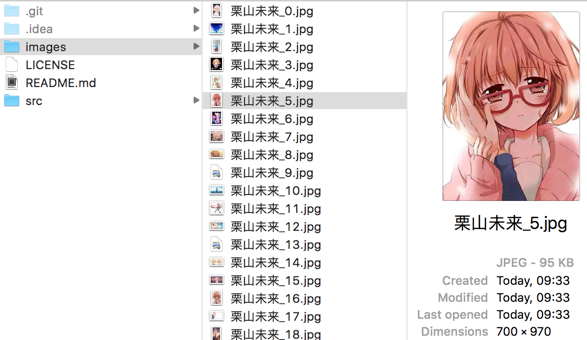
存放圖片的文件夾:
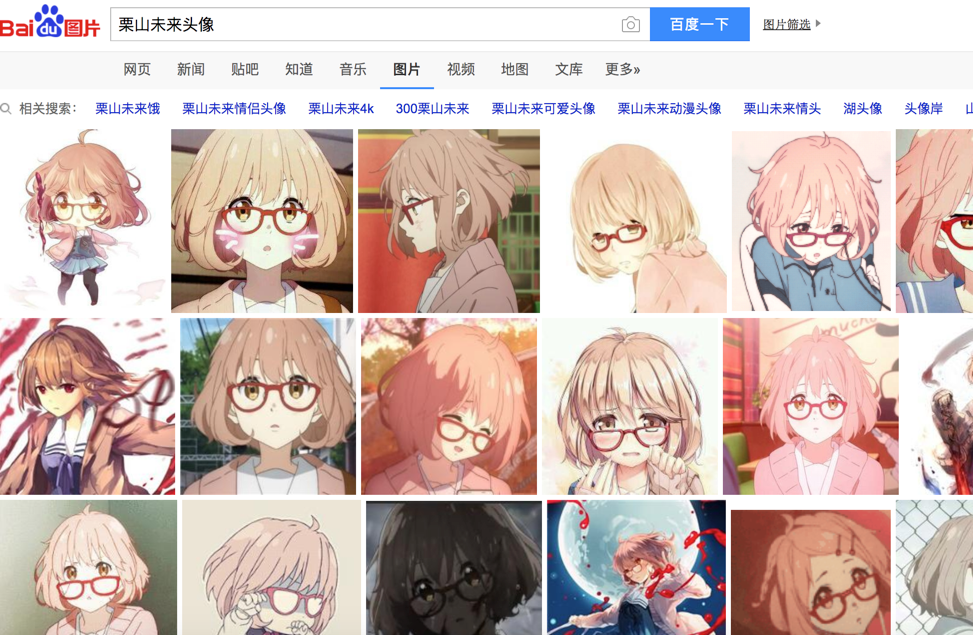
我們的爬蟲至少要實(shí)現(xiàn)兩個(gè)功能:一是搜索圖片,二是自動(dòng)下載。
搜索圖片:最容易想到的是爬百度圖片的結(jié)果,我們就上百度圖片看看:

隨便搜索幾個(gè)關(guān)鍵字,可以看到已經(jīng)搜索出來很多張圖片:
我們點(diǎn)擊右鍵,查看源代碼:
打開源代碼之后,發(fā)現(xiàn)一堆源代碼比較難找出我們想要的資源。
這個(gè)時(shí)候,就要用開發(fā)者工具!我們回到上一頁面,調(diào)出開發(fā)者工具,我們需要用的是左上角那個(gè)東西:(鼠標(biāo)跟隨)。
然后選擇你想看源代碼的地方,就可以發(fā)現(xiàn),下面的代碼區(qū)自動(dòng)定位到了相應(yīng)的位置。如下圖:
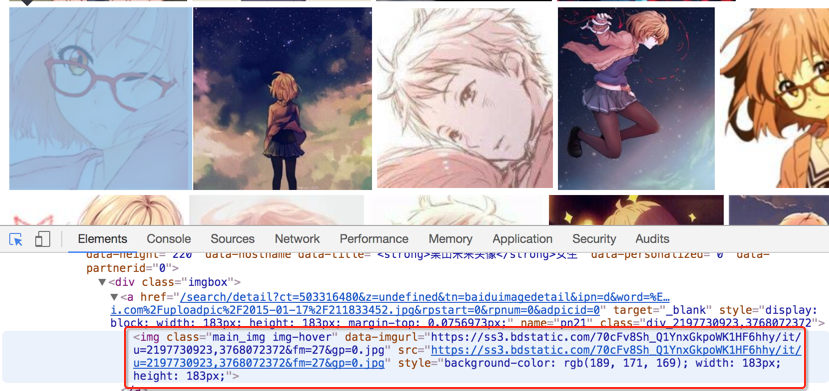

我們復(fù)制這個(gè)地址,然后到剛才的一堆源代碼里搜索一下,發(fā)現(xiàn)了它的位置,但是這里我們又疑惑了,這個(gè)圖片有這么多地址,到底用哪個(gè)呢?我們可以看到有thumbURL,middleURL,hoverURL,objURL

通過分析可以知道,前面兩個(gè)是縮小的版本,hoverURL 是鼠標(biāo)移動(dòng)過后顯示的版本,objURL 應(yīng)該是我們需要的,可以分別打開這幾個(gè)網(wǎng)址看看,發(fā)現(xiàn) objURL 的那個(gè)最大最清晰。
找到了圖片地址,接下來我們分析源代碼。看看是不是所有的 objURL 都是圖片。

發(fā)現(xiàn)都是以.jpg格式結(jié)尾的圖片。
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)這里我們用了2個(gè)包,一個(gè)是正則,一個(gè)是 requests 包
#-*- coding:utf-8 -*-import reimport requests
復(fù)制百度圖片搜索的鏈接,傳入 requests ,然后把正則表達(dá)式寫好

url = 'https://image.baidu.com/search/index?tn=baiduimage&ie=utf-8&word=%E6%A0%97%E5%B1%B1%E6%9C%AA%E6%9D%A5%E5%A4%B4%E5%83%8F&ct=201326592&ic=0&lm=-1&width=&height=&v=index' html = requests.get(url).text pic_url = re.findall('"objURL":"(.*?)",',html,re.S)因?yàn)橛泻芏鄰垐D片,所以要循環(huán),我們打印出結(jié)果來看看,然后用 requests 獲取網(wǎng)址,由于有些圖片可能存在網(wǎng)址打不開的情況,所以加了10秒超時(shí)控制。
pic_url = re.findall('"objURL":"(.*?)",',html,re.S) i = 1 for each in pic_url: print each try: pic= requests.get(each, timeout=10) except requests.exceptions.ConnectionError: print('【錯(cuò)誤】當(dāng)前圖片無法下載') continue
新聞熱點(diǎn)






疑難解答
圖片精選