在數(shù)據(jù)的處理過程中,一般都需要進行數(shù)據(jù)清洗工作,如數(shù)據(jù)集是否存在重復(fù),是否存在缺失,數(shù)據(jù)是否具有完整性和一致性,數(shù)據(jù)中是否存在異常值等.發(fā)現(xiàn)諸如此類的問題都需要針對性地處理,下面我們一起學(xué)習(xí)常用的數(shù)據(jù)清洗方法.
重復(fù)觀測處理
重復(fù)觀測:指觀測行存在重復(fù)的現(xiàn)象,重復(fù)觀測的存在會影響數(shù)據(jù)分析和挖掘結(jié)果的準(zhǔn)確性,所以在數(shù)據(jù)分析和建模之前需要進行觀測的重復(fù)性檢驗,如果存在重復(fù)觀測,
還需要進行重復(fù)項的刪除
在數(shù)據(jù)的收集過程中,可能會存在重復(fù)觀測的出現(xiàn),例如通過網(wǎng)絡(luò)爬蟲,就比較容易產(chǎn)生重復(fù)數(shù)據(jù).如下表,是通過爬蟲獲得某APP市場中電商類APP的下載量數(shù)據(jù)(部分)
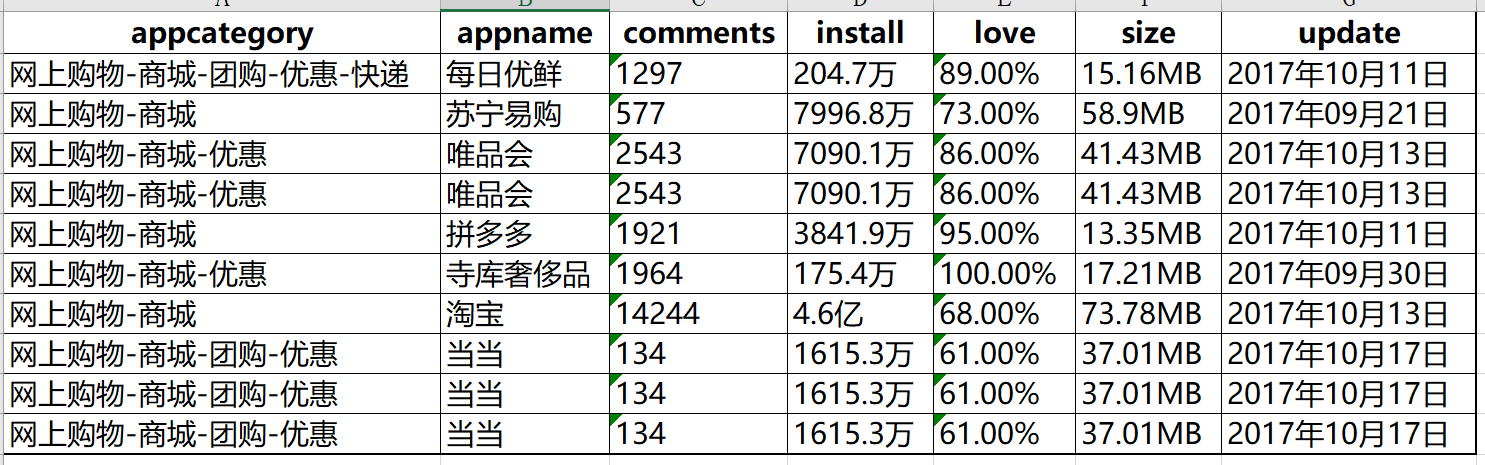
通過觀測可以看出唯品會和當(dāng)當(dāng)出現(xiàn)了三次.如果收集上來的不是10行,而是10萬行,甚至更多是,就無法通過肉眼的方式檢測數(shù)據(jù)是否存在重復(fù)項了.
下面我們看用python怎么來處理重復(fù)項的檢查,以及如何刪除數(shù)據(jù)項中的重復(fù)項
代碼:
import pandas as pddf = pd.read_excel(r'D:/data_test04.xlsx')print('數(shù)據(jù)集是否存在重復(fù)觀測: /n',any(df.duplicated()))out:
數(shù)據(jù)集是否存在重復(fù)觀測:
True
代碼就是簡單的兩行就處理好了
可以看出檢測數(shù)據(jù)集的記錄是否存在重復(fù),使用duplicated (英文單詞的意思就是重復(fù),復(fù)制的意思)方法,但是該方法返回的是數(shù)據(jù)集每一行的檢驗結(jié)果,為了能夠得到最直接的結(jié)果,可以使用any函數(shù),該函數(shù)表示的是在多個條件判斷中,只有一個條件為True,則any函數(shù)的結(jié)果就為True.正如結(jié)果所示,any函數(shù)的運用返回True值,說明
該數(shù)據(jù)集是存在重復(fù)觀測的.
刪除數(shù)據(jù)集中的重復(fù)觀測:
df.drop_duplicates(inplace = True)df
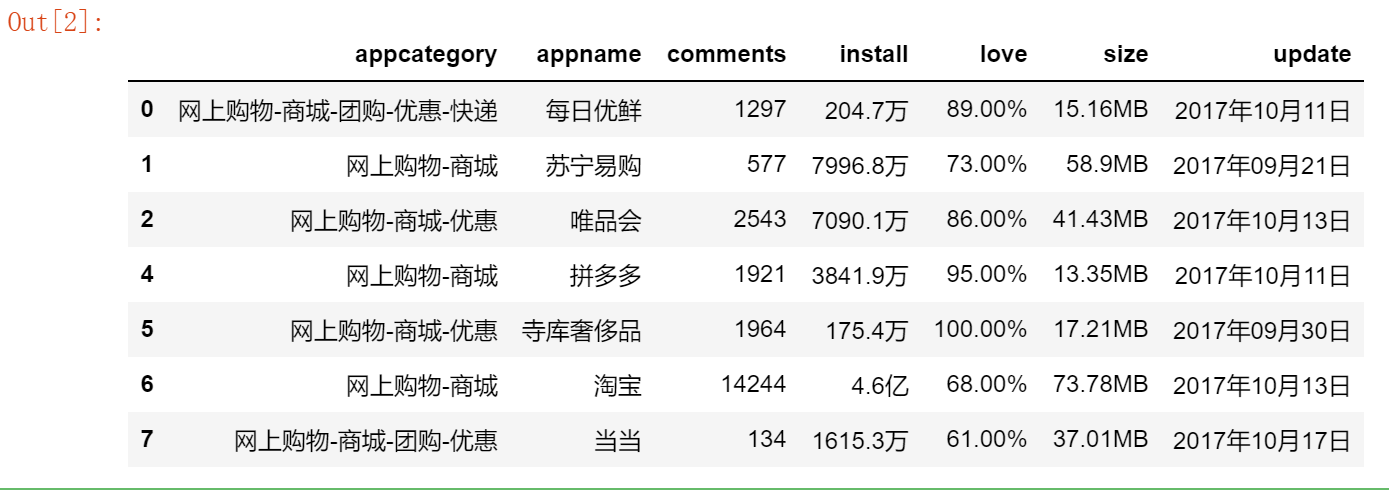
得出的結(jié)果如上圖所示,原先的10行在派出重復(fù)項后得到7行,被刪除的行號為:3,8和9.該方法中又有inplace參數(shù),設(shè)置為True就表示直接在原始數(shù)據(jù)集上做操作
以上就是本次介紹的全部知識點,感謝大家對武林網(wǎng)之家的支持。
新聞熱點






疑難解答