之所以起這樣一個題目是因為很久以前我曾經寫過一篇介紹TIME_WAIT的文章,不過當時基本屬于淺嘗輒止,并沒深入說明問題的來龍去脈,碰巧這段時間反復被別人問到相關的問題,讓我覺得有必要全面總結一下,以備不時之需。
討論前大家可以拿手頭的服務器摸摸底,記住「ss」比「netstat」快:
shell> ss -ant | awk '{++s[$1]} END {for(k in s) print k,s[k]}'如果你只是想單獨查詢一下TIME_WAIT的數量,那么還可以更簡單一些:
shell> cat /proc/net/sockstat
我猜你一定被巨大無比的TIME_WAIT網絡連接總數嚇到了!以我個人的經驗,對于一臺繁忙的Web服務器來說,如果主要以短連接為主,那么其TIME_WAIT網絡連接總數很可能會達到幾萬,甚至十幾萬。雖然一個TIME_WAIT網絡連接耗費的資源無非就是一個端口、一點內存,但是架不住基數大,所以這始終是一個需要面對的問題。
TCP在建立連接的時候需要握手,同理,在關閉連接的時候也需要握手。為了更直觀的說明關閉連接時握手的過程,我們引用「The TCP/IP Guide」中的例子:
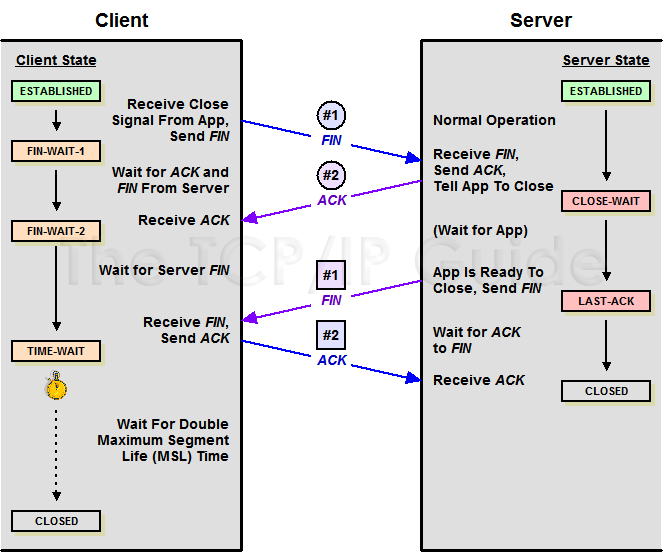
TCP Close
因為TCP連接是雙向的,所以在關閉連接的時候,兩個方向各自都需要關閉。先發FIN包的一方執行的是主動關閉;后發FIN包的一方執行的是被動關閉。主動關閉的一方會進入TIME_WAIT狀態,并且在此狀態停留兩倍的MSL時長。
穿插一點MSL的知識:MSL指的是報文段的最大生存時間,如果報文段在網絡活動了MSL時間,還沒有被接收,那么會被丟棄。關于MSL的大小,RFC 793協議中給出的建議是兩分鐘,不過實際上不同的操作系統可能有不同的設置,以Linux為例,通常是半分鐘,兩倍的MSL就是一分鐘,也就是60秒,并且這個數值是硬編碼在內核中的,也就是說除非你重新編譯內核,否則沒法修改它:
#define TCP_TIMEWAIT_LEN (60*HZ)
如果每秒的連接數是一千的話,那么一分鐘就可能會產生六萬個TIME_WAIT。
為什么主動關閉的一方不直接進入CLOSED狀態,而是進入TIME_WAIT狀態,并且停留兩倍的MSL時長呢?這是因為TCP是一個建立在不可靠網絡上的可靠的協議,主動關閉的一方收到被動關閉的一方發出的FIN包后,回應ACK包,同時進入TIME_WAIT狀態,但是因為網絡原因,主動關閉的一方發送的這個ACK包很可能延遲,從而觸發被動連接一方重傳FIN包。極端情況下,這一去一回,就是兩倍的MSL時長。如果主動關閉的一方跳過TIME_WAIT直接進入CLOSED,或者在TIME_WAIT停留的時長不足兩倍的MSL,那么當被動關閉的一方早先發出的延遲包到達后,就可能出現類似下面的問題:
不管是哪種情況都會讓TCP不在可靠,所以TIME_WAIT狀態有存在的必要性。
從前面的描述我們可以得出這樣的結論:TIME_WAIT這東西沒有的話不行,有的話太多也是個麻煩事。下面讓我們看看有哪些方法可以控制TIME_WAIT數量,這里只說一些常規方法,另外一些諸如SO_LINGER之類的方法太過偏門,略過不談。
ip_conntrack:顧名思義就是跟蹤連接。一旦激活了此模塊,就能在系統參數里發現很多用來控制網絡連接狀態超時的設置,其中自然也包括TIME_WAIT:
shell> modprobe ip_conntrackshell> sysctl net.ipv4.netfilter.ip_conntrack_tcp_timeout_time_wait
我們可以嘗試縮小它的設置,比如十秒,甚至一秒,具體設置成多少合適取決于網絡情況而定,當然也可以參考相關的案例。不過就我的個人意見來說,ip_conntrack引入的問題比解決的還多,比如性能會大幅下降,所以不建議使用。
tcp_tw_recycle:顧名思義就是回收TIME_WAIT連接。可以說這個內核參數已經變成了大眾處理TIME_WAIT的萬金油,如果你在網絡上搜索TIME_WAIT的解決方案,十有八九會推薦設置它,不過這里隱藏著一個不易察覺的陷阱:
當多個客戶端通過NAT方式聯網并與服務端交互時,服務端看到的是同一個IP,也就是說對服務端而言這些客戶端實際上等同于一個,可惜由于這些客戶端的時間戳可能存在差異,于是乎從服務端的視角看,便可能出現時間戳錯亂的現象,進而直接導致時間戳小的數據包被丟棄。參考:tcp_tw_recycle和tcp_timestamps導致connect失敗問題。
tcp_tw_reuse:顧名思義就是復用TIME_WAIT連接。當創建新連接的時候,如果可能的話會考慮復用相應的TIME_WAIT連接。通常認為「tcp_tw_reuse」比「tcp_tw_recycle」安全一些,官方文檔里是這樣說的:如果從協議視角看它是安全的,那么就可以使用。這簡直就是外交辭令啊!按我的看法,如果網絡比較穩定,比如都是內網連接,那么就可以嘗試使用,畢竟此時出現前面提的延遲包的可能性微乎其微。
不過需要注意的是在哪里使用,既然我們要復用連接,那么當然應該在連接的發起方使用,而不能在被連接方使用。舉例來說:客戶端向服務端發起HTTP請求,服務端響應后主動關閉連接,于是TIME_WAIT便留在了服務端,此類情況使用「tcp_tw_reuse」是無效的,因為服務端是被連接方,所以不存在復用連接一說。讓我們延伸一點來看,比如說服務端是PHP,它查詢另一個MySQL服務端,然后主動斷開連接,于是TIME_WAIT就落在了PHP一側,此類情況下使用「tcp_tw_reuse」是有效的,因為此時PHP相對于MySQL而言是客戶端,它是連接的發起方,所以可以復用連接。
tcp_max_tw_buckets:顧名思義就是控制TIME_WAIT總數。官網文檔說這個選項只是為了阻止一些簡單的DoS攻擊,平常不要人為的降低它。不過我覺得要分清主要矛盾是什么,如果TIME_WAIT已經成為最棘手的問題,那么即便此時并不是DoS攻擊的場景,我們也可以嘗試通過設置它來緩解主要矛盾。
通過設置它,系統會將多余的TIME_WAIT刪除掉,此時系統日志里可能會顯示:「TCP: time wait bucket table overflow」,多數情況下不用太在意這些信息。
需要提醒大家的是物極必反,曾經看到有人把「tcp_max_tw_buckets」設置成0,也就是說完全拋棄TIME_WAIT,這就有些冒險了,用一句圍棋諺語來說:入界宜緩。
…
有時候,如果我們換個角度去看問題,往往能得到四兩撥千斤的效果。前面提到的例子:客戶端向服務端發起HTTP請求,服務端響應后主動關閉連接,于是TIME_WAIT便留在了服務端。這里的關鍵在于主動關閉連接的是服務端!在關閉TCP連接的時候,先出手的一方注定逃不開TIME_WAIT的宿命,套用一句歌詞:把我的悲傷留給自己,你的美麗讓你帶走。如果客戶端可控的話,那么在服務端打開KeepAlive,保證服務端不會主動關閉連接,讓客戶端主動關閉連接,如此一來問題便迎刃而解了。
新聞熱點






疑難解答













