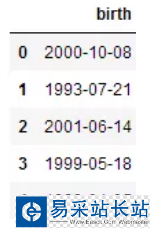
我們在做數據挖掘項目或大數據競賽時,如果個體是人的時候,獲得的數據中可能有出生日期的Series,舉個簡單例子,比如這樣的一些數:
# -*- coding: utf-8 -*-import pandas as pdfrom pandas import Series, DataFrameimport numpy as npimport seaborn as snsimport matplotlib.pyplot as plt %matplotlib inlinedata = {'birth': ['10/8/00', '7/21/93', '6/14/01', '5/18/99', '1/5/98']}frame = DataFrame(data)frame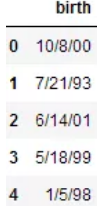
從數據來看,'10/8/00'之類的數,最左邊的數表示月份,中間的數表示日,最后的數表示年度。
實際上我們在分析時并不需要人的出生日期,而是需要年齡,不同的年齡階段會有不同的狀態,比如收入、健康、居住條件等等,且能夠很好地把不同樣本的差異性進行大范圍的劃分,而不是像出生日期那樣包含信息量過大且在算法訓練時不好作為有效數據進行訓練,age是一個很好地特征工程指示變量。
那如何把上述birth數據變為年齡age呢?
在這里用到datetime這個庫,如下:
(1)首先把birth轉化為標準時間格式
frame['birth'] = pd.to_datetime(frame['birth'])frame
(2)獲取當前時間的年份,并減去birth的年份
import datetime as dtnow_year =dt.datetime.today().year #當前的年份frame['age']=now_year-frame.birth.dt.yearframe
在這里使用了dt.datetime.today().year來獲取當前日期的年份,然后將birth數據中的年份數據提取出來(frame.birth.dt.year),兩者相減就得到需要的年齡數據,如下:

有時候我們可能還會關注到人的出生月份與要預測變量的關系,比如人的星座就是很流行的一種以出生月份、日份來評估其對人的影響,也可以按這種方法去提取月、日數據。
新聞熱點




疑難解答