介紹
本文將展示如何利用Python爬蟲來實現詩歌接龍。
該項目的思路如下:
利用爬蟲爬取詩歌,制作詩歌語料庫;
將詩歌分句,形成字典:鍵(key)為該句首字的拼音,值(value)為該拼音對應的詩句,并將字典保存為pickle文件;
讀取pickle文件,編寫程序,以exe文件形式運行該程序。
該項目實現的詩歌接龍,規則為下一句的首字與上一句的尾字的拼音(包括聲調)一致。下面將分步講述該項目的實現過程。
詩歌語料庫
首先,我們利用Python爬蟲來爬取詩歌,制作語料庫。爬取的網址為:https://www.gushiwen.org,頁面如下:
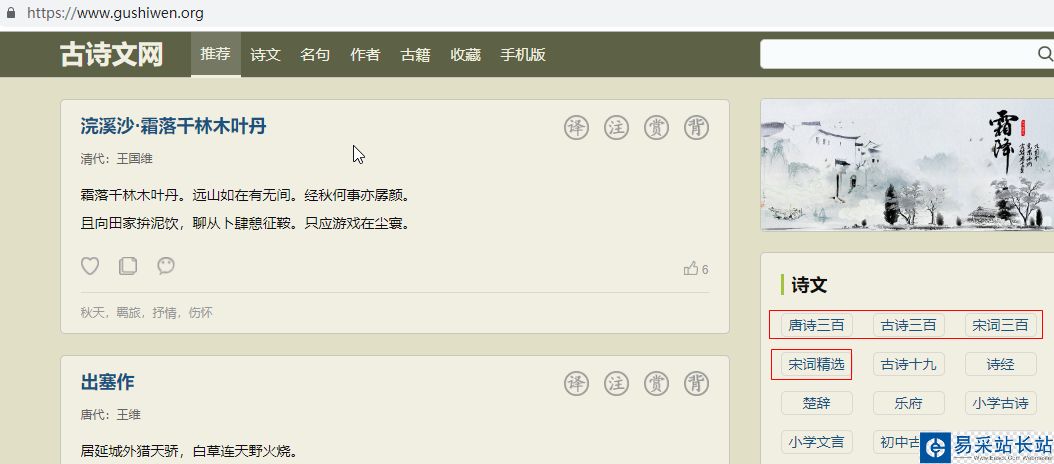
由于本文主要為試了展示該項目的思路,因此,只爬取了該頁面中的唐詩三百首、古詩三百、宋詞三百、宋詞精選,一共大約1100多首詩歌。為了加速爬蟲,采用并發實現爬蟲,并保存到poem.txt文件。完整的Python程序如下:
import reimport requestsfrom bs4 import BeautifulSoupfrom concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED# 爬取的詩歌網址urls = ['https://so.gushiwen.org/gushi/tangshi.aspx', 'https://so.gushiwen.org/gushi/sanbai.aspx', 'https://so.gushiwen.org/gushi/songsan.aspx', 'https://so.gushiwen.org/gushi/songci.aspx' ]poem_links = []# 詩歌的網址for url in urls: # 請求頭部 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'} req = requests.get(url, headers=headers) soup = BeautifulSoup(req.text, "lxml") content = soup.find_all('div', class_="sons")[0] links = content.find_all('a') for link in links: poem_links.append('https://so.gushiwen.org'+link['href'])poem_list = []# 爬取詩歌頁面def get_poem(url): #url = 'https://so.gushiwen.org/shiwenv_45c396367f59.aspx' # 請求頭部 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36'} req = requests.get(url, headers=headers) soup = BeautifulSoup(req.text, "lxml") poem = soup.find('div', class_='contson').text.strip() poem = poem.replace(' ', '') poem = re.sub(re.compile(r"/([/s/S]*?/)"), '', poem) poem = re.sub(re.compile(r"([/s/S]*?)"), '', poem) poem = re.sub(re.compile(r"。/([/s/S]*?)"), '', poem) poem = poem.replace('!', '!').replace('?', '?') poem_list.append(poem)# 利用并發爬取executor = ThreadPoolExecutor(max_workers=10) # 可以自己調整max_workers,即線程的個數# submit()的參數: 第一個為函數, 之后為該函數的傳入參數,允許有多個future_tasks = [executor.submit(get_poem, url) for url in poem_links]# 等待所有的線程完成,才進入后續的執行wait(future_tasks, return_when=ALL_COMPLETED)# 將爬取的詩句寫入txt文件poems = list(set(poem_list))poems = sorted(poems, key=lambda x:len(x))for poem in poems: poem = poem.replace('《','').replace('》','') / .replace(':', '').replace('“', '') print(poem) with open('F://poem.txt', 'a') as f: f.write(poem) f.write('/n')
新聞熱點




疑難解答