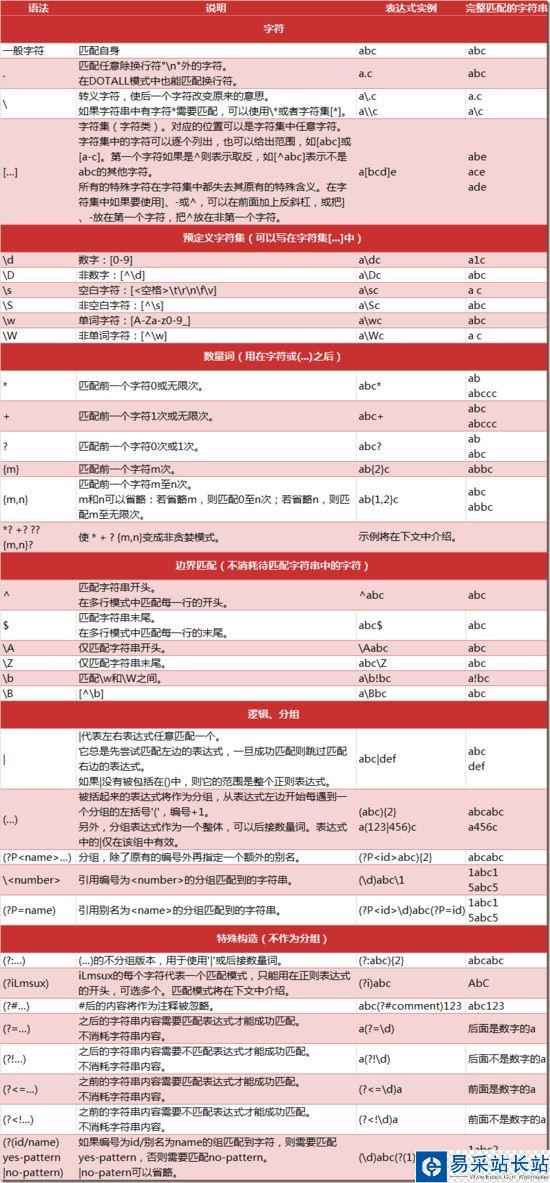
正則表達式的使用
re.match(pattern,string,flags=0)
re.match嘗試從字符串的起始位置匹配一個模式,如果不是起始位置匹配成功的話,match()就返回none
參數介紹:
pattern:正則表達式
string:匹配的目標字符串
flags:匹配模式
正則表達式的匹配模式:
最常規的匹配
import recontent ='hello 123456 World_This is a Regex Demo'print(len(content))result = re.match('^hello/s/d{6}/s/w{10}.*Demo$$',content)print(result)print(result.group()) #返回匹配結果print(result.span()) #返回匹配結果的范圍結果運行如下:
39
<_sre.SRE_Match object; span=(0, 39), match='hello 123456 World_This is a Regex Demo'>
hello 123456 World_This is a Regex Demo
(0, 39)
泛匹配
使用(.*)匹配更多內容
import recontent ='hello 123456 World_This is a Regex Demo'result = re.match('^hello.*Demo$',content)print(result)print(result.group())結果運行如下:
<_sre.SRE_Match object; span=(0, 39), match='hello 123456 World_This is a Regex Demo'>
hello 123456 World_This is a Regex Demo
匹配目標
在正則表達式中使用()將要獲取的內容括起來
使用group(1)獲取第一處,group(2)獲取第二處,如此可以提取我們想要獲取的內容
import recontent ='hello 123456 World_This is a Regex Demo'result = re.match('^hello/s(/d{6})/s.*Demo$',content)print(result)print(result.group(1))#獲取匹配目標結果運行如下:
<_sre.SRE_Match object; span=(0, 39), match='hello 123456 World_This is a Regex Demo'>
123456
貪婪匹配
import recontent ='hello 123456 World_This is a Regex Demo'result = re.match('^he.*(/d+).*Demo$',content)print(result)print(result.group(1))注意:.*會盡可能的多匹配字符
非貪婪匹配
import recontent ='hello 123456 World_This is a Regex Demo'result = re.match('^he.*?(/d+).*Demo$',content)print(result)print(result.group(1)) 注意:.*?會盡可能匹配少的字符
使用匹配模式
在解析HTML代碼時會有換行,這時我們就要使用re.S
import recontent ='hello 123456 World_This ' /'is a Regex Demo'result = re.match('^he.*?(/d+).*?Demo$',content,re.S)print(result)print(result.group(1))
新聞熱點




疑難解答