在我們使用一些數(shù)據(jù)的過(guò)程中,我們想要打亂數(shù)組內(nèi)數(shù)據(jù)的順序但不改變數(shù)據(jù)本身,可以通過(guò)改變索引值來(lái)實(shí)現(xiàn),也就是將索引值重新隨機(jī)排列,然后生成新的數(shù)組。功能主要由python中random模塊的sample()函數(shù)實(shí)現(xiàn)。
sample(population, k) method of random.Random instance Chooses k unique random elements from a population sequence or set.
下面的代碼實(shí)現(xiàn)的是打亂iris數(shù)據(jù),iris數(shù)據(jù)是網(wǎng)上下載的csv格式文件,相信大家不陌生的了,原始數(shù)據(jù)是三種鳶尾(iris)順序排列的,三種花分別是:setosa,versicolor 和 virginica ,記錄的數(shù)據(jù)有SepalLengthCm(花萼長(zhǎng)度), SepalWidthCm(花萼寬度), PetalLengthCm(花瓣長(zhǎng)度), PetalWidthCm (花瓣寬度)
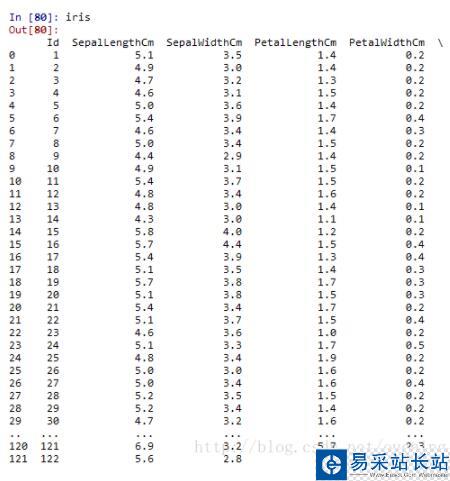
在做聚類(lèi)分析的時(shí)候曾經(jīng)用到過(guò)iris數(shù)據(jù),當(dāng)然,如果安裝了scikit learn 模塊的話,可以通過(guò)
from sklearn import datasetsiris = datasets.load_iris()
獲取
參考鏈接:http://scikit-learn.org/stable/auto_examples/datasets/plot_iris_dataset.html
下面的程序?qū)崿F(xiàn)打亂iris的數(shù)據(jù)順序:
import pandas as pdimport random as rd # 導(dǎo)入random模塊,使用里面的sample函數(shù)from pylab import *iris = pd.read_csv('D://Iris.csv')a1=reshape(iris['Id'],[150,1])a2=reshape(iris['SepalLengthCm'],[150,1])a3=reshape(iris['SepalWidthCm'],[150,1])data=c_[a1,a2,a3]idx=rd.sample(range(150),150) iris = data[idx] # 打亂順序,這里只選取了花萼長(zhǎng)度和寬度這兩個(gè)特征值2017/7/10 updated
打亂順序的方法還可以使用random.shuffle(iterable),這樣會(huì)直接改變iterable的順序,shuffle 是洗牌的意思,顧名思義,需要注意的是random.shufle()函數(shù)沒(méi)有返回值,如果寫(xiě)成
mylist = random.shuffle(list1)
將不會(huì)得到任何結(jié)果
以上這篇對(duì)Python random模塊打亂數(shù)組順序的實(shí)例講解就是小編分享給大家的全部?jī)?nèi)容了,希望能給大家一個(gè)參考,也希望大家多多支持武林站長(zhǎng)站。
新聞熱點(diǎn)




疑難解答
圖片精選