我們復(fù)制PDF到Google翻譯時(shí),總是會(huì)出現(xiàn)換行的情況,如果自己手動(dòng)去除,那就太麻煩了。
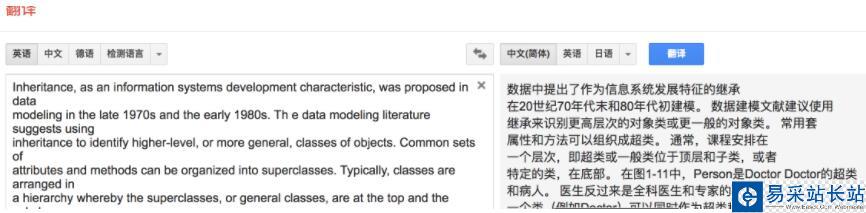
那么用Python就可以解決,復(fù)制到粘貼板以后,Python程序自動(dòng)可以把/n換成空格,然后我們就可以復(fù)制到Google翻譯中去
代碼:
import pyperclipimport timeimport webbrowsercopyBuff=' 'while True: time.sleep(10) copyedText=pyperclip.paste() if copyBuff!=copyedText: copyBuff=copyedText normalizedText = copyBuff.replace('/n', ' ') pyperclip.copy(normalizedText) else: print('no change')這樣一來(lái),其實(shí)還是有點(diǎn)麻煩,我們想如果復(fù)制完以后,自動(dòng)把復(fù)制內(nèi)容用谷歌翻譯就好了,所以稍微更改一下代碼
import pyperclipimport timeimport webbrowsercopyBuff=' 'while True: time.sleep(10) copyedText=pyperclip.paste() if copyBuff!=copyedText: copyBuff=copyedText normalizedText = copyBuff.replace('/n', ' ') url='https://translate.google.cn/#en/zh-CN/'+normalizedText #webbrowser.open(url)之前這么做的,默認(rèn)用Safari打開(kāi),404 not found #所以要用chrome打開(kāi)就OK啦 w = webbrowser.get('chrome') w.open(url) else: print('no change')完美!
以上這篇淺談python實(shí)現(xiàn)Google翻譯PDF,解決換行的問(wèn)題就是小編分享給大家的全部?jī)?nèi)容了,希望能給大家一個(gè)參考,也希望大家多多支持武林站長(zhǎng)站。
新聞熱點(diǎn)




疑難解答
圖片精選