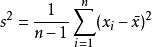單總體t檢驗是檢驗一個樣本平均數與一個已知的總體平均數的差異是否顯著。當總體分布是正態分布,如總體標準差未知且樣本容量小于30,那么樣本平均數與總體平均數的離差統計量呈t分布。 (--百度百科)
在單樣本的情況下,假設數據x1,x2,...,xn來自于服從N(μ,σ2)的獨立隨機變量。我們希望對假設μ=μ0進行檢驗。
對n個均值為μ,標準差為σ的隨機變量求平均值,使用均值的標準誤(SEM,standard Error of the Mean)來描述這個均值的波動性,它的表達式是:SEM= σ/sqrt(n)
對于服從正態分布的數據,有一般性準則:有95%的數據會落在μ±2σ這個區間里。所以如果μ0是真實的平均數,那么x均就應該落在μ0±2SEM中。通過計算 t = (x均-μ0)/SEM來判定t是否落在了一個接受域中。
t應該以一定的概率落在這個接受域之外,這個概率被稱為顯著性水平。如果t落在接受域之外,那么我們就在預設的顯著性水平上拒絕零假設。另一種等價的方法是計算p值,它指的是得到一個絕對值上大于或等于當前t值的概率,我們在p值小于顯著性水平的情況下拒絕零假設。
有時候我們需要對樣本數據的均值進行單邊檢驗,即判定μ是落在右邊區域(偏大)還是左邊區域(偏小)。
在R中可以使用t.test()函數 來進行單樣本t檢驗。其形式如下:
t.test(x, y = NULL, alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, var.equal = FALSE, conf.level = 0.95, ...)
其中,x為非空數值型向量;y是可選的數值型向量;
alternative是字符型字符串,用于指定備擇假設方法,其中two.sided是雙邊檢驗,less是左側單邊檢驗,greater是右側單邊檢驗;
mu是數據的真實均值;
paired是一個邏輯值,用于指定是否進行配對檢驗,默認為FALSE;
var.equal是一個邏輯值,用于指定兩個方差是否相等(a logical variable indicating whether to treat the two variances as being equal. If TRUE then the pooled variance is used to estimate the variance otherwise the Welch (or Satterthwaite) approximation to the degrees of freedom is used.)
conf.level指定置信水平,默認為0.95.
(1)雙邊檢測的例子
某種元件的壽命x(小時),服從正態分布N(μ,σ2),其中mu,σ2均未知,其中抽樣的16只元件的壽命如下:
159,280,101,212,224,379,179,264,222,362,168,250,149,260,485,170
問是否有理由認為元件的平均壽命等于250小時?
原假設H0:μ = 250;備擇假設H1:μ≠250
編寫R程序如下:
#定義變量
x<-c(159,280,101,212,224,379,179,264,222,362,168,250,149,260,485,170)
#進行單樣本t檢驗
t.test(x,mu=250)
運行結果如下:

結果解讀:
結果中第1行是標題“單樣本t檢驗”;第2行給出了使用的數據變量:x;第3行計算了t值,給出了自由度df,和p值;第4行是備擇假設:真實值不等于250;緊接著第5和第6行是95%的置信區間[188.89,294.11];最后3行是樣本估計,數據x的均值是241.5。
從產生的結果來看,p-value=0.7353>0.05,所以不能拒絕原假設H0(μ=250),即這些樣本壽命的均值在0.05的顯著性水平下與250沒有顯著區別。
(2)單邊檢測的例子
環保標準規定汽車的新排放標準:平均值<20ppm,現某汽車公司測試10輛汽車的排放結果如下:
15.6, 16.2, 22.5, 20.5, 16.4,19.4,16.6, 17.9, 12.7,13.9
問題:公司引擎排放是否滿足新標準。
原假設H0:μ>=20;備擇假設:μ<20;
編寫R語言程序如下:
#定義變量x
x<-c(15.6,16.2,22.5,20.5,16.4,19.4,16.6,17.9,12.7,13.9)
#進行單樣本單邊檢測(less)
t.test(x,mu=20,alternative="less")
運行結果如下:

結果解讀:
p-value = 0.0075<0.05,則拒絕原假設,亦即選擇備擇假設:μ<20.也就是說,該題中的汽車符合排放標準。
新聞熱點






疑難解答