集智導讀:
本文會為大家展示機器學習專家 Mike Shi 如何用 50 行 Python 代碼創建一個 AI,使用增強學習技術,玩耍一個保持桿子平衡的小游戲。所用環境為標準的 OpenAI Gym,只使用 Numpy 來創建 agent。
各位看官好,我(作者 Mike Shi——譯者注)將在本文教大家如何用 50 行 Python 代碼,教會 AI 玩一個簡單的平衡游戲。我們會用到標準的 OpenAI Gym 作為測試環境,僅用 Numpy 創建我們的 AI,別的不用。
這個小游戲就是經典的 Cart Pole 任務,它是 OpenAI Gym 中一個經典的傳統增強學習任務。游戲玩法如下方動圖所示,就是盡力保持這根桿子始終豎直向上。桿子由于重力原因,會出現傾斜,到了一定程度就會倒下,AI 的任務就是在此時向左或向右移動桿子,不讓它倒下。這就跟我們在手指尖上樹立一支鉛筆玩“金雞獨立”一樣,只不過我們這里是個一維的簡單游戲(但是還是很有挑戰性的)。
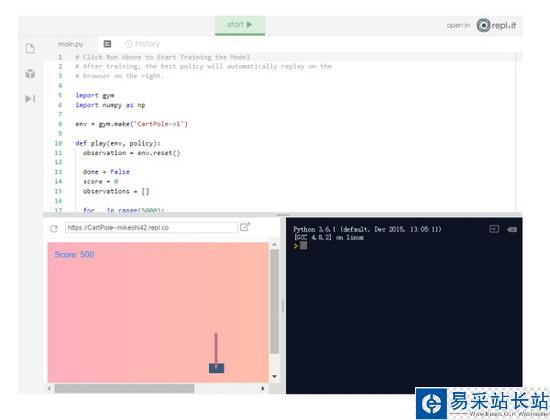
你可能好奇最終實現怎樣的結果,可以在repl.it 上查看 demo:
https:// repl.it/@MikeShi42/Cart Pole
增強學習速覽
如果這是你第一次接觸機器學習或增強學習,別擔心,我下面介紹一些基礎知識,這樣你就可以了解本文使用的術語了:)。如果已經熟悉了,大可跳過這部分,直接看看編寫 AI 的部分。
增強學習(RL)是一個研究領域:教 agent(我們的算法/機器)執行某些任務/動作,但明確告訴它該怎樣做。把它想象成一個嬰兒,以隨機的方式伸腿,如果寶寶偶然間走運站立起來,我們會給它一個糖果作為獎勵。同樣,Agent 的目標就是在其生命周期內得到最多的獎勵,而且我們會根據是否和要完成的任務相符來決定獎勵的類型。對于嬰兒站立的例子,站立時獎勵 1,否則為0。
增強學習 agent 的一個著名例子是 AlphaGo,其中的 agent 已經學會了如何玩圍棋以最大化其獎勵(贏得游戲)。在本教程中,我們將創建一個 agent,或者說 AI,可以向左或向右移動小車,讓桿子保持平衡。
狀態
狀態是目前游戲的樣子。我們通常處理游戲的多種數字表示。在乒乓球比賽中,它可能是每個球拍的垂直位置和 x,y 坐標和球的速度。在我們這個游戲中,我們的狀態由 4 個數字組成:底部小車的位置,小車的速度,桿的位置(以角度表示)和桿的角速度。這 4 個數字都是給定的數組(或向量)。這個很重要,理解狀態是一個數字數組意味著我們可以對它進行一些數學運算來決定我們根據狀態采取什么行動。
新聞熱點




疑難解答