XML數據庫探討2
2024-07-21 02:08:12
供稿:網友
同樣的,對于xml數據庫(就是native-xml數據庫,以下簡稱xmldb)來說也有很多難于跨越的鴻溝,導致了經過這么多年的發展,最終卻一直沒有壯大。參考網站:http://www-900.ibm.com/developerworks/cn/xml/x-xdata/part5/index.shtml#1 的敘述,關于xmldb現在有以下一些問題:(以下是引用的內容)存儲
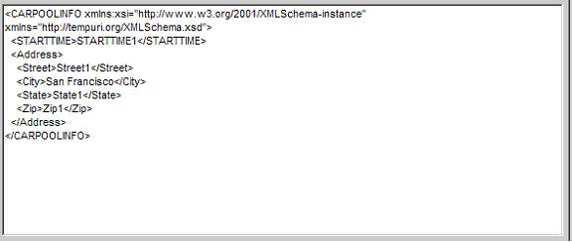
在資源庫中存儲信息很簡單。如果希望存儲的信息已經是 xml 格式,那么可以直接把它添加進資源庫。這也許聽起來不錯。畢竟在不斷創新的 web 服務世界中,將要到來的多數信息將使用嵌入在 soap 消息中的 xml 片段格式。然而,把 xml 文檔分解并保存到關系數據庫一點也不困難;當開始查看希望支持的其它功能時,這種作法會有一些好處。同樣許多本 native-xml 數據庫供應商所鼓吹的一個好處是 native-xml 數據庫能夠存儲和查詢異種的文檔結構。再說,對于結構化數據問題在于:您真的希望信息的結構千變萬化嗎?對于使用 xml 文檔時具有的這種優勢,當使用結構化數據時就算不上是一種優勢了。檢索
初看上去,從 native-xml 數據庫檢索信息似乎也是一個好處:以信息的原始 xml 格式檢索它,而不需任何附加的編碼,并且可以使信息以一定的樣式顯示。然而,結構化數據檢索的性質使得這種明顯的優勢實際上變成了劣勢。如果信息更新量巨大(例如,接收單個數兆字節大小 xml 文檔的股票系統的夜間更新),一些 native-xml 平臺需要從數據庫返回整個文檔 — 即使您只對文檔的很小一部分感興趣(譬如某個特定股票的變化過程)。 其它 native-xml 平臺在將 xml 文檔保存到資源庫之前進行分解,但是如果具有復雜的文檔結構(正如許多結構化 xml 文檔傾向于具有這種結構)時,這樣做就顯得有點笨拙。無論如何,許多關系數據庫供應商目前正在實現瘦 xml 序列化器包裝器以便支持在需要時從關系數據生成 xml 文檔。這使得程序員可以容易地獲得完成特定任務所恰好需要的信息,這些信息具有某種格式,這種格式具有所需樣式、或者可以發送給其它能識別 xml 的目標。搜索
搜索 native-xml 數據庫有兩種常規解決方法可用,選取哪種取決于數據庫供應商。一些 native-xml 數據庫需要選擇哪些元素或屬性用于索引,如同在關系數據庫里選擇哪些列用于索引。然后,這個信息被用于建立索引,以便搜索機制能用來快速定位相匹配的文檔。在文檔被添加到資源庫時,其它 native-xml 數據庫就是對文檔內的所有信息建索引,可以想象這將導致存儲空間需求飛速上升(想象一下在關系數據庫中對所有列建索引!)。由于這些數據庫以文檔為中心的性質,搜索將返回一組 xml 文檔;然后如有必要,調用程序還得對這些文檔做進一步處理。 很遺憾的是,這意味著更復雜的搜索,是很不方便的。例如,要找出那個對某一特定部分提交最高訂單的顧客,以為在中間環節要處理很多事情。在指向關系方面 native-xml 數據庫做的也不好。結果是,如果數據結構不是純粹層次結構的,則對您而言,native-xml 數據庫就不是恰當的解決方案。大多數 native-xml 數據庫具有這一功效強大的特性 — 執行完善的全文搜索的能力,包括整個同義字支持、字根(匹配一個字的所有形式:現在時、過去時和進行時)以及相近搜索(dtd near xml schema)。此外,在使用傳統文檔時,這些特性是不可缺少的,其中上下文在含意上起著重要的作用,而當使用結構化數據時,就遠沒有那么重要了。聚合
使用關系數據工作時,聚合是所需要的最重要功能之一,事實上它處于聯機分析處理的核心(olap)。native-xml 數據庫在執行聚合任務方面表現得特別差。因為信息要么被保持在文檔這一層,要么一般被分割成節點,所以把信息匯集起來以及集中處理它(求和、平均數等等)就很困難,此外,還必須在中間環節增加附加代碼。如果結構化數據應用程序需要任何一種分析處理 — 我打賭它會需要 — native-xml 數據庫將會使您失望。