XML在更多的時候只是一種數據文件,怎樣將它變為我們日常所看到的HTML格式那樣的文件呢?如果我們將XML文件比作結構化的原料的話,那么XSL就好比“篩子“與“模子“,篩子選取自己需要的原料,這些原料再通過模子形成最終的產品:HTML。
這個模子大致是這樣:我們先設計好表現的頁面,再將其中需要從XML中獲取數據來填充內容的部分“挖掉“,然后用XSL語句從XML中篩出相關的數據來填充。一言以譬之:這XSL實際上就是HTML的一個“殼子“,XML數據利用這個“殼“來生成“傳統“的HTML。
XML在展開時是一個樹形結構,我們將樹形結構中自定義標記稱為節點,節點之間存在父子、兄弟關系,我們要訪問其中的結點從根結點就要以”/”來層層進入。
在XSL這個殼中,我們要從原料庫??XML里提取相關的數據,就要用到XSL提供的模式化查詢語言。所謂模式化查詢語言,就是通過相關的模式匹配規則表達式從XML里提取數據的特定語句,即我們上所說的“篩子“。
參考微軟的”XSL開發者指南”,我們大致可將模式語言分為三種:
(1)選擇模式 < xsl:for-each >、< xsl:value-of >,和 < xsl:apply-templates >
(2)測試模式 < xsl:if > 和< xsl:when >
(3)匹配模式 < xsl:template >
我們現在就分別對之進行介紹。
1、 選擇模式
選擇模式語句將數據從XML中提取出來,是一種簡單獲得數據的方法,這幾個標記都有一個select屬性,選取XML中特定的結點名的數據。
(1)< xsl:for-each >
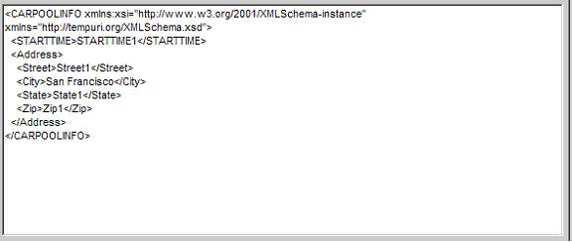
如在XML中有這樣的數據:
< author >
< name >翔宇< /name >
< name >無憂< /name >
< name >飛翔< /name >
< /author >
我們要讀取這三個作者名字,是一個一個地按”author/name”方法來讀取嗎,可有多個這樣的name呀?如果有一種程序性的語句來循環讀取有多好啊!
想得很對,XSL提供了這樣的具有程序語言性質的語句< XSL:for-each >
用它讀取這三個作者名字的方法如下:
< xsl:for-each select=”author/name” >
…….
< ./xsl:for-each >
select? 名思義:選取,它可以選定XML中特定唯一的標記,也可以選擇某一類相同的標記,我們稱之為結點集。
語法:
< xsl:for-each select="pattern" order-by="sort-criteria-list">
屬性:
1). select
根據XSL樣式查詢考察上下文以決定哪類結點集(滿足select條件)使用此樣式描述。作為一種簡化的表示就是,如果你想對文檔中的某一種標記的內容的顯示方式進行格式化,就可以將讓select等于此元素的標記名。例如欲對標記xml_mark進行格式化,即可用如下方式表示:
< xsl:for-each select="xml_mark" >
< !--樣式定義-- >
< /xsl:for-each >
2). order-by
以分號(;)分隔、作為排序標準的列表。在列表元素前添加加號(+)表示按此標記的內容以升序排序,添加減號(-)表示逆序排序。作為一種簡化的表示就是,排序標準列表就是由select規定的標記的子標記的序列,每個標記之間以(;)分隔。
(2)、< xsl:value-of >
< xsl:for-each >模式只是選取節點,并沒有取出節點的值,好比猴子只是爬到了樹的某個枝干上,那么就用< xsl:value-of >來摘“勝利果實“吧!
語法:
< xsl:value-of select="pattern" >提取節點的值
屬性:
select用來與當前上下文匹配的XSL式樣。簡單的講,如果要在XSL文檔某處插入某個XML標記(假定是xml_mark標記)的內容,可用如下方式表示:
< xsl:value-of select="xml_mark" >< /xsl:value-of >
或
< xsl:value-of select="xml_mark"/ >
示例:
此處仍以上期的個人簡歷的作為例子,我們需要對文件(個人簡歷.xml)作一定修改,確切的說是將其中的第二行
< ?xml:stylesheet type="text/css" href=http://www.blue1000.com/article/"resume.css"? >
修改為
< ?xml:stylesheet type="text/xsl" href=http://www.blue1000.com/article/"resume.xsl"? >
然后建立一個新文件:resume.xsl,其內容如下:
< ?xml version="1.0" encoding="GB2312"? >
< HTML xmlns:xsl="http://www.w3.org/TR/WD-xsl" >
< HEAD >
< TITLE >網站簡介< /TITLE >
< /HEAD >< BODY >
< xsl:for-each select="resume" >
< P/ >
< TABLE border="1" cellspacing="0" >
< CAPTION style="font-size: 150%; font-weight: bold" >
網站簡介
< /CAPTION >
< TR >
< TH >網站名稱< /TH >< TD >< xsl:value-of select="name"/ >< /TD >
< TH >網站性質< /TH >< TD >< xsl:value-of select="sex"/ >< /TD >
< TH >創建日期< /TH >< TD >< xsl:value-of select="birthday"/ >< /TD >
< /TR >
< TR >
< TH >網站功能< /TH >< TD colspan="5" >< xsl:value-of select="skill"/ >< /TD >
< /TR >
< /TABLE >
< /xsl:for-each >
< /BODY >
< /HTML >
完成這些以后再來讓我們看一下辛勤勞動的成果,怎么樣?效果不錯吧。更酷還在后頭呢。現在我們對文件(個人簡歷.xml)作進一步的修改:
1. 在標記< resume >前添加一個新標記< document >;
2. 將標記對< resume >< /resume >之間的內容(包括這一對標記)復制并粘貼在其后,并在最后用< document >結束。
3. 以Notepad.exe打開文件resume.xsl,在標記< HTML >之后添加文字:< xsl:for-each select="document" >;在標記< /HTML >之前添加文字:< /xsl:for-each >,保存文件。
4. 在瀏覽器中打開文件(個人簡歷.xml)。看到了什么?兩份個人簡歷!
就這樣,利用XML我們可以編寫內容與樣式完成分離的文檔!當然,XSL文件比一般的HTML文件要復雜一些,然而一旦完成則可用于格式化所有同類的XML文檔。
注:如果拷貝代碼,請將空ge刪除
新聞熱點






疑難解答