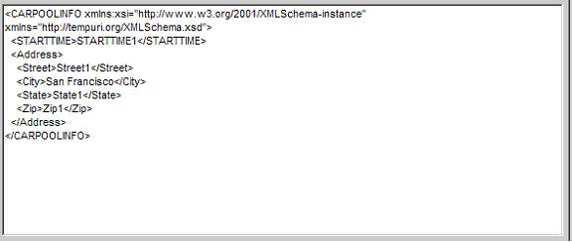
在網絡時代,xml文件起到了一個保存和傳輸數據的作用。soap協議通過xml交流信息,數據庫通過xml文件存取等等。那么怎樣快速的從一個xml文件中取得所需的信息呢?
我們知道,java的jaxp中和microsoft.net都有xml分析器,microsoft.net是邊讀邊分析,而jaxp是讀到內存中然后才進行分析(還有一種是事件機制去讀),總而言之,是不利于快速讀取。基于此,microsoft.net 和jaxp都提供了xpath機制,來快速定位到xml文件中所需的節點。
例如有一個xml文件:booksort.xml:
<?xml version="1.0"?>
<!-- a fragment of a book store inventory database -->
<bookstore xmlns:bk="urn:samples">
<book genre="novel" publicationdate="1997" bk:isbn="1-861001-57-8">
<title>pride and prejudice</title>
<author>
<first-name>jane</first-name>
<last-name>austen</last-name>
</author>
<price>24.95</price>
</book>
<book genre="novel" publicationdate="1992" bk:isbn="1-861002-30-1">
<title>the handmaid's tale</title>
<author>
<first-name>margaret</first-name>
<last-name>atwood</last-name>
</author>
<price>29.95</price>
</book>
<book genre="novel" publicationdate="1991" bk:isbn="1-861001-57-6">
<title>emma</title>
<author>
<first-name>jane</first-name>
<last-name>austen</last-name>
</author>
<price>19.95</price>
</book>
<book genre="novel" publicationdate="1982" bk:isbn="1-861001-45-3">
<title>sense and sensibility</title>
<author>
<first-name>jane</first-name>
<last-name>austen</last-name>
</author>
<price>19.95</price>
</book>
</bookstore>
共4頁: 上一頁 1 [2] [3] [4] 下一頁
新聞熱點






疑難解答