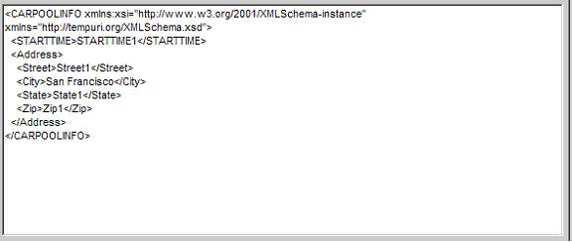
當我們要把xml格式的數據存到數據庫中。通常的辦法是解析xml文件,讀出xml中的數據類型并根據它創建數據庫表和表之間的結構,讀出xml中的數據,存入到數據庫之中。
在讀nodeType是要注意二個問題:
1.讀某個節點數據類型可以對上一個節點的孩子,或直接使本節點的類型,只不過要嚴格注意定位正確,不要混淆。
例:link.getElementsByTagName("link").item(0).getFirstChild().getNodeType()
2.對于nodetype的值,如果一般可以得到數據,也可以是與Node類的靜態屬性值相配的。
如:Node.DOCUMENT_NODE
Node.ELEMENT_NODE
Node.CDATA_SECTION_NODE
Node.TEXT_NODE
好像與0,1,2,3相對應,自己可以測試一下。
其實上面的方法并不是一件可取的方法,一種比較好的替代方法是:
1.使用xnlSchema來描述該xml文件。
2.對schema文件進行xml解析,獲得實體及其類型,然后根據實體名和類型來創建表,根據實體之間的關系,設定表之間的關系。
3.用xmldom或sxap來解析xml文件,提取數據,存入數據庫中。
新聞熱點






疑難解答