本文摘自博客園的博文,該文詳細地介紹了并行數據的知識,特轉載到這里。
1.并行數據庫的體系結構
并行機的出現,催生了并行數據庫的出現,不對,應該是關系運算本來就是高度可并行的。對數據庫系統性能的度量主要有兩種方式:
(1)吞吐量(Throughput),在給定的時間段里所能完成的任務數量;
(2)響應時間(Response time),單個任務從提交到完成所需要的時間。
對于處理大量小事務的系統,通過并行地處理許多事務可以提高它的吞吐量。對于處理大事務的系統,通過并行的執行事務的子任務,可以縮短系統晌應時間。
并行機有三種基本的體系結構,相應的,并行數據庫的體系結構也可以大概分為三類:
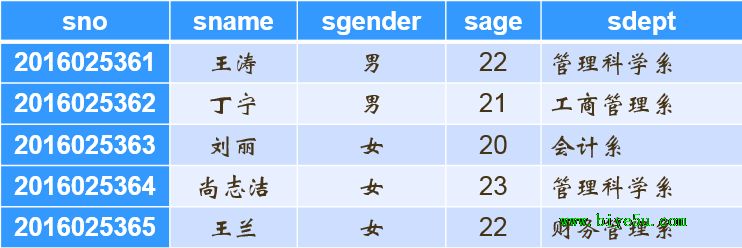
? 共享內存(share memeory):所有處理器共享一個公共的存儲器;(如圖1所示)
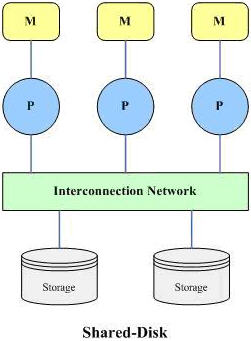
? 共享磁盤(share disk):所有處理器共享公共的磁盤;這種結構有時又叫做集群(cluster);(如圖2所示)
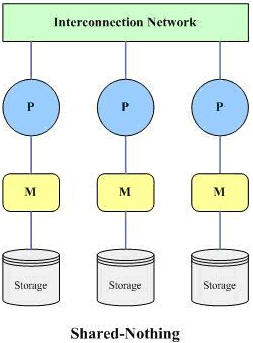
? 無共享(share nothing):所有處理器既不共享內存,也不共享磁盤。(如圖3所示)
如圖所示:
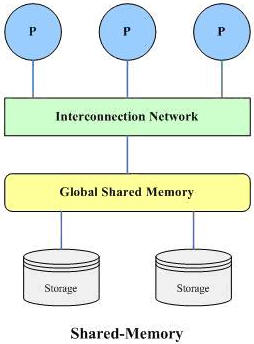
(1)、 共享內存
該結構包括多個處理器、一個全局共享的內存(主存儲器)和多個磁盤存儲,各個處理器通過高速通訊網絡(Interconnection Network)與共享內存連接,并均可直接訪問系統中的一個、多個或全部的磁盤存儲,在系統中,所有的內存和磁盤存儲均由多個處理器共享。
這種結構的優點在于,處理器之間的通信效率極高,訪問內存的速度要比消息通信機制要快很多。這種結構的缺點在于,處理器的規模不能超過32個或者64個,因為總線或互邊網絡是由所有的處理器共享,它會變成瓶頸。當處理器數量到達某一個點時,再增加處理器已經沒有什么好處。
共享內存結構通常在每個處理器上有很大的高速緩存,從而減少對內存的訪問。但是,這些高速緩存必須保持一致,也就是緩存一致性(cache-coherency)的問題。
(2)、 共享磁盤
該結構由多個具有獨立內存(主存儲器)的處理器和多個磁盤存儲構成,各個處理器相互之間沒有任何直接的信息和數據的交換,多個處理器和磁盤存儲由高速通信網絡連接,每個處理器都可以讀寫全部的磁盤存儲。
共享磁盤與共享內存結構相比,有以下一些優點:
(1)每個處理器都有自己的存儲器,存儲總線不再是瓶頸;
(2)以一種較經濟的方式提供了容錯性(fault tolerence),如果一個處器發生故障,其它處理器可以代替工作。
該結構的主要問題不是在于可擴展性問題,雖然存儲總線不是瓶頸,但是,與磁盤之間的連接又成了瓶頸。
運行Rdb的DEC集群是共享磁盤的體系結構的早期商用化產品之一(DEC后來被Compaq公司收購,再后來,Oracle又從Compaq手中取得Rdb,發展成現在的Oracle RAC)。
(3)、 無共享
該結構由多個完全獨立的處理節點構成,每個處理節點具有自己獨立的處理器、獨立的內存(主存儲器)和獨立的磁盤存儲,多個處理節點在處理器級由高速通信網絡連接,系統中的各個處理器使用自己的內存獨立地處理自己的數據。
這 種結構中,每一個處理節點就是一個小型的數據庫系統,多個節點一起構成整個的分布式的并行數據庫系統。由于每個處理器使用自己的資源處理自己的數據,不存 在內存和磁盤的爭用,提高的整體性能。另外這種結構具有優良的可擴展性——只需增加額外的處理節點,就可以以接近線性的比例增加系統的處理能力。
這種結構中,由于數據是各個處理器私有的,因此系統中數據的分布就需要特殊的處理,以盡量保證系統中各個節點的負載基本平衡,但在目前的數據庫領域,這個數據分布問題已經有比較合理的解決方案。
由于數據是分布在各個處理節點上的,因此,使用這種結構的并行數據庫系統,在擴展時不可避免地會導致數據在整個系統范圍內的重分布(Re-Distribution)問題。
Shared-Nothing結構的典型代表是Teradata(并行數據庫的先驅),值得一提的是,MySQL NDB Cluster也使用了這種結構。
2、I/O并行(I/O Parallelism)
I/O并行的最簡單形式是通過對關系劃分,放置到多個磁盤上來縮減從磁盤讀取關系的時間。并行數據庫中數據劃分最通用的形式是水平劃分(horizontal portioning),一個關系中的元組被劃分到多個磁盤。
(1)、常用劃分技術
假定將數據劃分到n個磁盤D0,D1,…,Dn中。
(1) 輪轉法(round-bin)。對關系順序掃描,將第i個元組存儲到標號為Di%n的磁盤上;該方式保證了元組在多個磁盤上均勻分布。
(2) 散列劃分(hash partion)。選定一個值域為{0, 1, …,n-1}的散列函數,對關系中的元組基于劃分屬性進行散列。如果散列函數返回i,則將其存儲到第i個磁盤。
(3) 范圍劃分(range partion)。
由于將關系存儲到多個磁盤,讀寫時能同時進行,劃分(partion)能大大提高系統的讀寫性能。數據的存取可以分為以下幾類:
1) 掃描整個關系;
2) 點查詢(point query),如name = “hustcat”;
3) 范圍查詢(range query),如 20 < age < 30。
不同的劃分技術,對這些存取類型的效率是不同的:
? 輪轉法適合順序掃描關系,對點查詢和范圍查詢的處理較復雜。
? 散列劃分特別適合點查詢,速度最快。
? 范圍劃分對點查詢、范圍查詢以及順序掃描都支持較好,所以適用性很廣。但是,這種方式存在一個問題——執行偏斜(execution skew),也就是說某些范圍的元組較多,使得大量的I/O出現在某幾個磁盤。
3、查詢間并行(interquery parallism)
查詢間并行指的是不同的查詢或事務間并行的執行。這種形式的并行可以提高事務的吞吐量,然而,單個事務并不能執行得更快(即響應時間不能減少)。查詢間的并行主要用于擴展事務處理系統,在單位時間內能夠處理更多的事務。
查詢間并行是數據庫系統最易實現的一種并行,在共享內存的并行系統(如SMP)中尤其這樣。為單處理器設計的數據庫系統可以不用修改,或者很少修改就能用到共享內存的體系結構。
在共享磁盤和無共享的體系結構中,實現查詢間并行要更復雜一些。各個處理需要協調來進行封鎖、日志操作等等,這就需要處理器之間的傳遞消息。并行數據庫系統必須保證兩個處理器不會同時更新同一數據。而且,處理器訪問數據時,系統必須保證處理器緩存的數據是最新的數據,即緩存一致性問題。
4、查詢內并行(intraquery parallism)
查詢內并行是指單個查詢要在多個處理器和磁盤上同時進行。為了理解,來考慮一個對某關系進行排序的查詢。假設關系已經基于某個屬性進行了范圍劃分,存儲于多個磁盤上,并且劃分是基于劃分屬性的。則排序操作可以如下進行:對每個分區并行的排序,然后將各個已經有序的分區合并到一起。
單個查詢的執行可以有兩種并行方式:
(1) 操作內并行(Intraoperation parallism):通過并行的執行每一個運算,如排序、選擇、連接等,來加快一個查詢的處理速度。
(2) 操作間并行(Interoperation parallism):通過并行的執行一個查詢中的多個不同的運算,來加速度一個查詢的處理速度。
注意兩者間的區別,前者可以認為多個處理器同時執行一個運算,而后者是多個處理器同時執行不同的運算。
這兩種形式之間的并行是互相補充的,并且可以同時存在于一個查詢中。通常由于一個查詢中的運算數目相對于元組數目是較小的,所以當并行度增加時,第一種方式取得的效果更顯著。
新聞熱點






疑難解答