前言
在數(shù)據(jù)庫系統(tǒng)中,大對象往往是指這樣一種類型的數(shù)據(jù):這些數(shù)據(jù)的體積較大,占用的字節(jié)數(shù)在KB級或MB級,有的甚至達(dá)到GB級。對于DBMS來說,這些數(shù)據(jù)不具備結(jié)構(gòu)性,只是單純的字節(jié)流,存儲時需一次性存入,讀取時需一次性取出。日常生活中常見的圖片、事頻、音頻以及大數(shù)據(jù)量大文本文件,都屬于大對象數(shù)據(jù)的范疇。現(xiàn)有的各種關(guān)系型數(shù)據(jù)庫管理系統(tǒng)也都提供了豐富的數(shù)據(jù)類型和完備的存取方法來管理大對象數(shù)據(jù)。毫無疑問,作為大型通用的數(shù)據(jù)庫管理系統(tǒng),達(dá)夢數(shù)據(jù)庫為大對象的存儲類型提供了全面的支持,在大對象數(shù)據(jù)的存儲組織方式上采用B樹結(jié)合從表的方式達(dá)到了很好的存取效率。然而,與Oracle的大對象存取效率相比,達(dá)夢數(shù)據(jù)庫還有差距。為此,達(dá)夢數(shù)據(jù)庫開發(fā)部門在近期對達(dá)夢數(shù)據(jù)庫的存取策略進(jìn)行了改進(jìn)和優(yōu)化。測試結(jié)果表明,優(yōu)化后的達(dá)夢數(shù)據(jù)庫在大對象存取效率方面與Oracle相比,要略微勝出。本文詳細(xì)討論了達(dá)夢數(shù)據(jù)庫大對象存取優(yōu)化的方法和思路,其目的主要有兩個:(1)為使用達(dá)夢數(shù)據(jù)庫的廣大開發(fā)人員詳細(xì)解釋系統(tǒng)中大對象的存取方法,使他們能夠基于達(dá)夢數(shù)據(jù)庫開發(fā)出高效的應(yīng)用系統(tǒng);(2)拋磚引玉,向廣大開發(fā)人員介紹達(dá)夢數(shù)據(jù)庫,希望能夠引起更多人的關(guān)注,獲得更多的改進(jìn)建議。
1.1 大對象存儲組織方式及其不足
不同于Oracle的簇存儲方式,達(dá)夢數(shù)據(jù)庫中,大對象數(shù)據(jù)的存儲結(jié)構(gòu)采用和普通數(shù)據(jù)一樣的B樹結(jié)構(gòu)。對于每一個具有大對象字段的表(稱之為主表),系統(tǒng)會為其設(shè)置一個從表,此表專門用來存儲這個表的大對象數(shù)據(jù)。
當(dāng)往主表插入一條含大對象的記錄時,系統(tǒng)將判斷此記錄的大小是否超過950字節(jié),如果小于950字節(jié),那么系統(tǒng)將這條記錄直接插入到主表之中;反之,將這條記錄中的大對象數(shù)據(jù)插入到從表之中。系統(tǒng)中同時規(guī)定,從表中每條記錄的DATA字段的最大值為950個字節(jié),如果一個大對象數(shù)據(jù)超過950B,那么需要將這個大對象劃分成若干分片,每個數(shù)據(jù)分片表1中的其余三個字段組成一條從表記錄插入到從表中。
原有系統(tǒng)的這種做法簡單易行,在基本的存儲模塊上增加了分片模塊和重新組裝模塊即可實(shí)現(xiàn)了對大對象的存取。然而,這種做法有兩個缺陷。
1.從表記錄中數(shù)據(jù)分片允許的最大值太小(為950個字節(jié)),導(dǎo)致一個體積較大的大對象在存儲時,需要被分解成很多分片,在提取該大對象時,又需要重新組裝眾多分片。這些操作將耗費(fèi)大量CPU時間。
2.數(shù)據(jù)分片的最大值太小還導(dǎo)致了空間利用率過低。達(dá)夢數(shù)據(jù)庫中,從表中的ROWID,COLID,F(xiàn)RAGID字段長度分別為8,2,4字節(jié),每條物理記錄另有控制信息26字節(jié)。這樣,從表中每個數(shù)據(jù)分片需要有40個字節(jié)的數(shù)據(jù)來進(jìn)行標(biāo)識。假設(shè)需要往某主表插入100萬個大小為1K的大對象,由于1KB > 950B,每個大對象都需要拆成兩條記錄插入到從表中。簡單計(jì)算可以得出,存儲每個大對象需要的額外字節(jié)為80B,100萬個大對象,共1GB大約需要80MB額外空間,將近有10%的空間被用來標(biāo)識大對象的數(shù)據(jù)分片,由此可以看出空間浪費(fèi)較為嚴(yán)重。
將數(shù)據(jù)分片的最大值設(shè)定為950字節(jié)是沒有必要的。可以將這個值適當(dāng)放大,減少將大對象分片重新組裝分片消耗的時間,以及提高空間利用率。
1.2 大對象的寫日志機(jī)制及其不足
達(dá)夢數(shù)據(jù)庫中日志包括redo日志和undo日志。目前的系統(tǒng)中,在插入大對象數(shù)據(jù)時,redo日志的生成和處理方式和一般的數(shù)據(jù)插入是完全一樣的,undo日志則進(jìn)行了優(yōu)化。下面首先對這兩種機(jī)制進(jìn)行簡要的介紹。
1.2.1 redo日志的處理
達(dá)夢數(shù)據(jù)庫中的redo日志記錄了系統(tǒng)的對數(shù)據(jù)塊的更新動作,我們可以按照redo日志,重做系統(tǒng)的每一步操作,保證系統(tǒng)的一致性。在系統(tǒng)正常工作時,每當(dāng)往表中插入一條物理記錄時,便會生成一條redo日志。在一個事務(wù)提交之前,系統(tǒng)將首先把系統(tǒng)緩沖區(qū)中的redo日志寫入到磁盤中,然后再提交事務(wù)。通過這種方式,可以保證系統(tǒng)發(fā)生故障的時候,能夠通過redo日志來恢復(fù)數(shù)據(jù),保證系統(tǒng)數(shù)據(jù)的完整性和一致性。
對于每一條要插入的物理記錄,在將其插入到數(shù)據(jù)頁之前都會構(gòu)造一條對應(yīng)的redo日志記錄,redo日志記錄的結(jié)構(gòu)是一個六元組:
(dbid, file_id, page_no, offset, len, new_data)
其中,前4個參數(shù)是為了標(biāo)識日志記錄對應(yīng)的物理記錄在文件中所處的數(shù)據(jù)塊的地址和塊內(nèi)偏移,參數(shù)new_data為正式數(shù)據(jù),保存物理記錄的記錄頭+記錄體信息。參數(shù)len表示new_data數(shù)據(jù)的長度。
系統(tǒng)在每次故障后重啟時,使用上次運(yùn)行時在日志文件中產(chǎn)生的redo日志記錄,根據(jù)記錄中dbid, file_id, page_no, offset四個字段的信息,找到記錄對應(yīng)的物理記錄所在的數(shù)據(jù)塊中的地址,并用new_data來覆蓋這個物理記錄。這樣就可以保證系統(tǒng)故障前提交的事務(wù)對數(shù)據(jù)庫的更新操作得到執(zhí)行。
1.2.2 undo日志的處理
達(dá)夢數(shù)據(jù)庫中,undo日志機(jī)制可以確保系統(tǒng)崩潰后重啟時,系統(tǒng)能消除未提交事務(wù)對系統(tǒng)造成的影響。系統(tǒng)為每個事務(wù)分配有若干回滾段,事務(wù)對數(shù)據(jù)進(jìn)行修改操作時會在回滾段中生產(chǎn)相應(yīng)的回滾記錄。如果事務(wù)成功提交,回滾段將被拋棄,如果事務(wù)被回滾,系統(tǒng)將利用回滾段將數(shù)據(jù)庫中的數(shù)據(jù)恢復(fù)到事務(wù)開始前的狀態(tài)。為了在系統(tǒng)故障或掉電等情況下,回滾段中的數(shù)據(jù)不會丟失,回滾段的數(shù)據(jù)記錄在數(shù)據(jù)庫文件而不是在內(nèi)存中。
系統(tǒng)對插入大對象時的undo日志生成方法進(jìn)行了優(yōu)化。對于普通數(shù)據(jù),每往表中插入一條記錄,系統(tǒng)會為記錄生成回滾記錄并保存到回滾段中;對于大對象數(shù)據(jù),將大對象分片并插入到從表時,對于從表中具有同樣rowid和colid的記錄,僅對fragid = 0的記錄生成回滾記錄。在回滾時,根據(jù)回滾記錄上rowid和colid,對從表的所有具有相同rowid和colid的記錄進(jìn)行回滾。顯然,這種做法能夠保證插入操作的正確回滾。
綜上所述,系統(tǒng)在往從表插入大對象數(shù)據(jù)時,redo日志的生成方法和普通數(shù)據(jù)是完全一樣的,而undo日志則進(jìn)行了優(yōu)化。可以結(jié)合大對象數(shù)據(jù)插入的特點(diǎn),參考undo日志在這方面的優(yōu)化方法,來對大對象插入的redo日志生成機(jī)制進(jìn)行優(yōu)化。
2.1 大對象存儲組織的優(yōu)化
原有系統(tǒng)將從表中大對象數(shù)據(jù)的體積的最大值限定為950字節(jié)是不合理的。可以考慮將這個值適當(dāng)擴(kuò)大。顯然,從表記錄允許存放的大對象體積越大,大對象存取的時間越短,空間利用率也越高。為此,可以考慮將從表中大對象體積的最大值放大到一個極限的位置。下面討論這個極限值如何確定。
達(dá)夢數(shù)據(jù)庫對記錄大小的限制是,系統(tǒng)內(nèi)部任何物理記錄的最大值不能超過塊長一半。這種規(guī)定是為了確保一條物理記錄只在一個物理塊中,保證一個B樹節(jié)點(diǎn)至少有兩條物理記錄,避免B樹退化成鏈表結(jié)構(gòu)。由此可知,從表中記錄的大小不能超過塊長一半。由于大對象從表的結(jié)構(gòu)中,前三個字段的大小取值是固定的,因此,在從表記錄大小不超過塊長一半的前提下,能夠精確地計(jì)算出從表記錄中大對象體積的最大值。計(jì)算方法在此從略。顯然,通過擴(kuò)大從表記錄中大對象體積的最大值,可以減少大對象分片和分片重組的時間,提高空間利用率。
2.2 大對象寫日志機(jī)制的優(yōu)化
分析寫日志機(jī)制可以看出,插入大對象數(shù)據(jù)到從表中時,為每一條物理記錄生成完整的redo日志記錄是沒有必要的。一種可行的優(yōu)化思路是:
1.在redo日志記錄中只保存從表物理記錄的rowid,colid和fraid字段,而不需要DATA字段既大對象數(shù)據(jù)。這種做法由于不用保存大對象數(shù)據(jù),減少了redo日志的數(shù)據(jù)量,提高了寫日志的速度,進(jìn)而減少大對象數(shù)據(jù)插入所消耗的時間。
2.記錄插入過程中,保存了從表物理記錄的數(shù)據(jù)塊的塊號,在大對象插入結(jié)束之后,事務(wù)提交之前,首先將插入操作生成的redo日志刷盤,然后將這些塊刷盤。
顯然,這種redo日志優(yōu)化方法將提高大對象插入的效率。下面從對事務(wù)的redo和undo操作兩個方面來說明這種優(yōu)化方法可以保證數(shù)據(jù)的正確性。
1.對于在故障前已提交的事務(wù),故障恢復(fù)時需要恢復(fù)而不是撤銷事務(wù)對數(shù)據(jù)庫的更新操作。在系統(tǒng)重啟后,由于上次系統(tǒng)運(yùn)行時往從表中插入的物理記錄已經(jīng)在事務(wù)提交之前被刷盤,所以此時(既系統(tǒng)重啟后)從表中的記錄都是完整和正確的,此時再使用redo日志記錄來覆蓋物理記錄,只不過是將物理記錄的前三個字段重新寫入數(shù)據(jù)塊而已,不會造成數(shù)據(jù)的丟失,雖然redo日志記錄并沒有記錄大對象數(shù)據(jù)。
2.對于在故障前未提交的事務(wù),故障恢復(fù)時需要撤銷事務(wù)對數(shù)據(jù)庫的改動。此時,首先打開redo日志文件,從事務(wù)的開始點(diǎn)出發(fā),正向掃描redo日志文件,使用redo日志記錄中的rowid,colid和fraid替換表中的相應(yīng)物理記錄的這三個字段,直到故障發(fā)生的地方停止替換。然后再使用undo日志文件從故障發(fā)生的地方開始,反向利用回滾記錄將具有與回滾記錄相同rowid和colid的物理記錄恢復(fù)到事務(wù)開始前的狀態(tài)。這樣,事務(wù)對從表的插入操作被成功撤銷。
由此可見,采用這種方法完全可以在系統(tǒng)發(fā)生故障后保證數(shù)據(jù)的正確性。這種優(yōu)化方案是完全可行的。優(yōu)化方案的具體做法如下:
(1)修改redo日志生成機(jī)制。優(yōu)化前的系統(tǒng)對從表的insert操作,為物理頁上的所有改動生成日志記錄并寫入日志文件。優(yōu)化后,RREC記錄上只記錄不包含分片數(shù)據(jù)的其他修改;
(2)將大對象插入到從表時記錄被修改的從表數(shù)據(jù)頁號;
(3)往從表插入一個大對象結(jié)束以后,將redo日志刷盤;
(4)將redo日志刷盤后,將插入過程中修改的從表數(shù)據(jù)頁全部刷盤。
2.3 寫日志機(jī)制優(yōu)化的補(bǔ)充說明
完成redo日志優(yōu)化的優(yōu)化工作后,在性能測試中我們發(fā)現(xiàn),對redo日志生成機(jī)制進(jìn)行優(yōu)化并不能百分百地減少大對象插入的時間。當(dāng)插入的大對象數(shù)據(jù)量較小時,優(yōu)化后插入所消耗的時間反而要大于優(yōu)化前。出現(xiàn)這種現(xiàn)象的原因是,優(yōu)化后,每插入一個大對象數(shù)據(jù)都需要將從表中的相應(yīng)數(shù)據(jù)頁刷盤,刷盤將引起大量I/O操作,這將為日志生成增加額外的時間,數(shù)據(jù)量小的情況下,增加的時間將超過由于優(yōu)化減少的時間。
針對這個問題,我們設(shè)計(jì)了以下解決方案:
(1)由應(yīng)用系統(tǒng)開發(fā)人員來決定是否需要對大對象存儲進(jìn)行日志生成優(yōu)化。如果需要存儲的大對象數(shù)據(jù)量不是很大(建議值為小于100K),可以指定不進(jìn)行日志優(yōu)化,如果需要存儲的大對象數(shù)據(jù)量比較大,可以指定進(jìn)行日志優(yōu)化。
(2)系統(tǒng)中增加一個存儲過程,用戶可以調(diào)用此存儲過程來指定是否對日志生成進(jìn)行優(yōu)化。
(3)如果要插入的大對象數(shù)據(jù)類型是TEXT,系統(tǒng)默認(rèn)不對日志進(jìn)行優(yōu)化,如果插入的大對象數(shù)據(jù)類型是BLOB,系統(tǒng)默認(rèn)對日志進(jìn)行優(yōu)化。
最后給出優(yōu)化前后的測試對比結(jié)果。由于本次優(yōu)化工作的目標(biāo)是縮小DM5.6相對于Oracle9i在大對象存取效率上的差異,因此首先給出優(yōu)化前的DM5.6與Oracle9i的大對象存取速度對比結(jié)果,然后給出DM5.6優(yōu)化前后的大對象存取速度對比結(jié)果。通過比較Oracle9i和優(yōu)化后的DM5.6在在大對象存取速度上相對于優(yōu)化前DM5.6的提升率,可以間接比較Oracle9i和優(yōu)化后的DM5.6在大對象存取上的時間效率的差異。
3.1 優(yōu)化前DM與Oracle的大對象存取性能對比
(1)相關(guān)配置說明
硬件配置:
CPU(個數(shù)) Pentium cpu 2.66GHz
內(nèi)存 1G
操作系統(tǒng) WINXP
數(shù)據(jù)庫版本:
ORACLE ORACLE 9i
DM 優(yōu)化前的DM5.6
內(nèi)部參數(shù):
ORACLE 默認(rèn)配置
DM 默認(rèn)配置
測試數(shù)據(jù):
大對象數(shù)據(jù)采用大小為5M 的MPG格式文件。測試時,分別往數(shù)據(jù)庫中插入1-64條,共5-320MB大對象數(shù)據(jù)。測試結(jié)果取三次的平均值。
(2)ODBC方式插入大對象
測試程序采用ODBC方式連接數(shù)據(jù)庫,每插入一條數(shù)據(jù)便提交一次事務(wù)。首先給出優(yōu)化前的DM5.6與Oracle9i的大對象插入速度對比結(jié)果。

圖1 優(yōu)化前的DM5.6和Oracle9i的大對象插入速度對比
(3)ODBC方式讀取大對象
接下來給出優(yōu)化前的DM5.6與Oracle9i的大對象讀取速度對比結(jié)果。
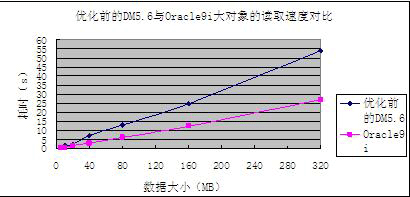
圖2 優(yōu)化前的DM5.6和Oracle9i的大對象讀取速度對比
3.2 優(yōu)化前后DM大對象存取性能對比
(1)相關(guān)配置說明
硬件配置:
CPU(個數(shù)) 酷睿雙核1.6GHz
內(nèi)存 1G
操作系統(tǒng) WINXP
數(shù)據(jù)庫版本:
DM 優(yōu)化前的DM5.6
DM 優(yōu)化后的DM5.6
內(nèi)部參數(shù):
ORACLE 默認(rèn)配置
DM 默認(rèn)配置
測試數(shù)據(jù):
在內(nèi)存中生成1MB的大對象數(shù)據(jù),測試時往數(shù)據(jù)庫中插入1-500條大對象記錄。測試結(jié)果取三次的平均值。
(2)ODBC方式插入大對象
測試程序采用ODBC方式連接數(shù)據(jù)庫,每插入一條數(shù)據(jù)便提交一次事務(wù)。首先給出優(yōu)化前后的DM5.6大對象插入速度對比結(jié)果。

圖3 優(yōu)化前后的DM5.6大對象插入速度對比
(3)ODBC方式讀取大對象
接下來給出優(yōu)化前后的DM5.6大對象讀取速度對比結(jié)果。
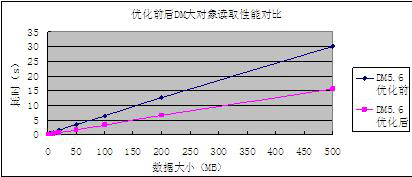
圖4 優(yōu)化前后的DM5.6大對象讀取速度對比
3.3 結(jié)果分析
通過四個對比測試可以得出以下結(jié)論:
(1)優(yōu)化前的DM5.6與Oracle9i在大對象插入速度上相差不大,平均來說,Oracle9i要快10%左右;但是在讀取速度上,優(yōu)化前的DM5.6要比Oracle9i慢接近1倍;
(2)優(yōu)化后的DM5.6在大對象插入速度有大幅提升,從圖3可以看到,優(yōu)化后的DM5.6要比優(yōu)化前快約30%左右;在讀取速度上,優(yōu)化后的DM5.6比優(yōu)化前快90%左右,接近1倍,基本上與Oracle9i的讀取速度基本持平。
最后的結(jié)論是,此次優(yōu)化工作取得了令人滿意的結(jié)果。
新聞熱點(diǎn)






疑難解答